Changelog
UI Redesign and Configuration Management and Overview View
22 August 2024
v0.24.0
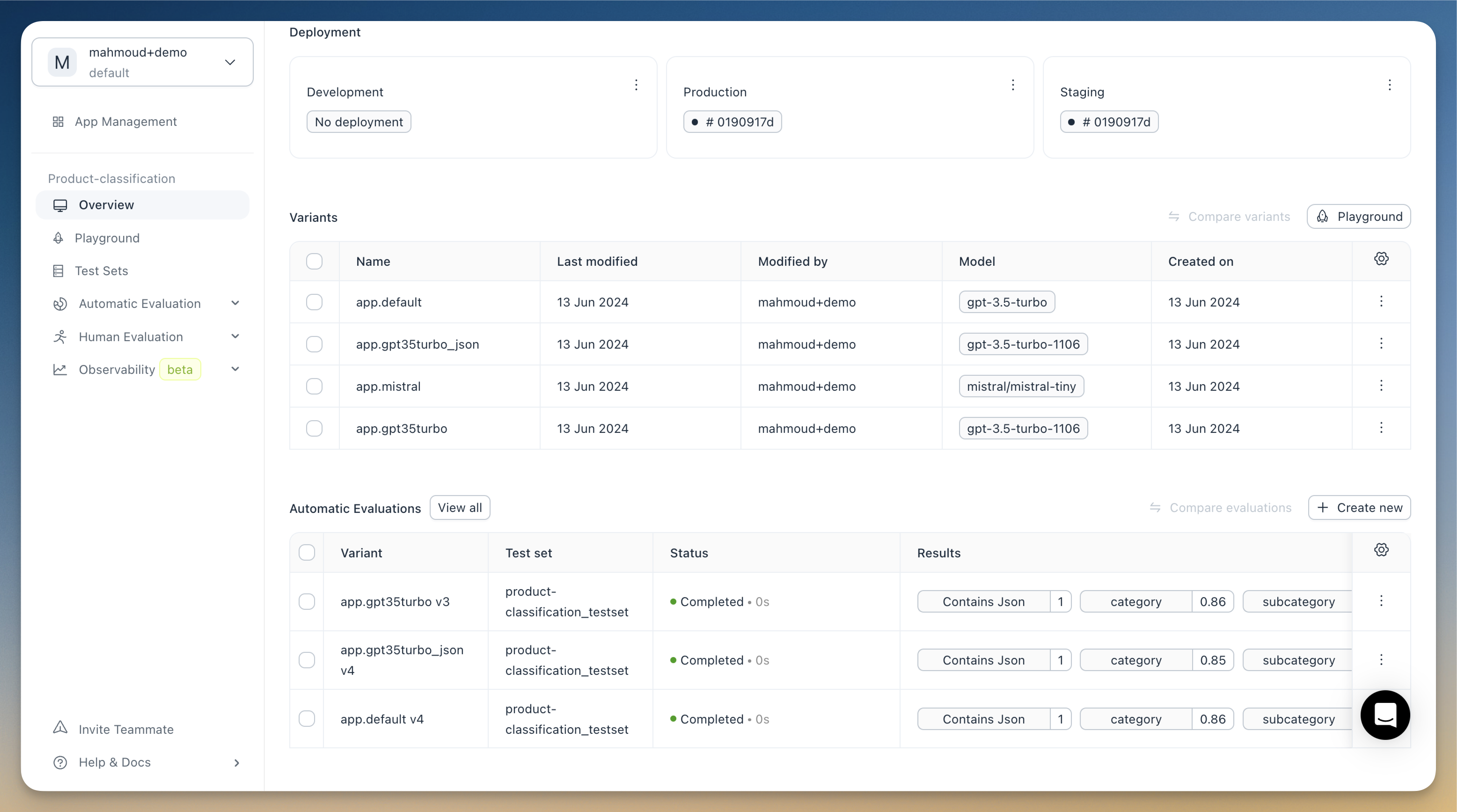
We've completely redesigned the platform's UI. Additionally we have introduced a new overview view for your applications. This is part of a series of upcoming improvements slated for the next few weeks.
The new overview view offers:
- A dashboard displaying key metrics of your application
- A table with all the variants of your applications
- A summary of your application's most recent evaluations
We've also added a new JSON Diff evaluator. This evaluator compares two JSON objects and provides a similarity score.
Lastly, we've updated the UI of our documentation.
New Alpha Version of the SDK for Creating Custom Applications
20 August 2024
v0.23.0
We've released a new version of the SDK for creating custom applications. This Pydantic-based SDK significantly simplifies the process of building custom applications. It's fully backward compatible, so your existing code will continue to work seamlessly. We'll soon be rolling out comprehensive documentation and examples for the new SDK.
In the meantime, here's a quick example of how to use it:
import agenta as ag
from agenta import Agenta
from pydantic import BaseModel, Field
ag.init()
# Define the configuration of the application (that will be shown in the playground )
class MyConfig(BaseModel):
temperature: float = Field(default=0.2)
prompt_template: str = Field(default="What is the capital of {country}?")
# Creates an endpoint for the entrypoint of the application
@ag.route("/", config_schema=MyConfig)
def generate(country: str) -> str:
# Fetch the config from the request
config: MyConfig = ag.ConfigManager.get_from_route(schema=MyConfig)
prompt = config.prompt_template.format(country=country)
chat_completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=config.temperature,
)
return chat_completion.choices[0].message.content
RAGAS Evaluators and Traces in the Playground
12 August 2024
v0.22.0
We're excited to announce two major features this week:
-
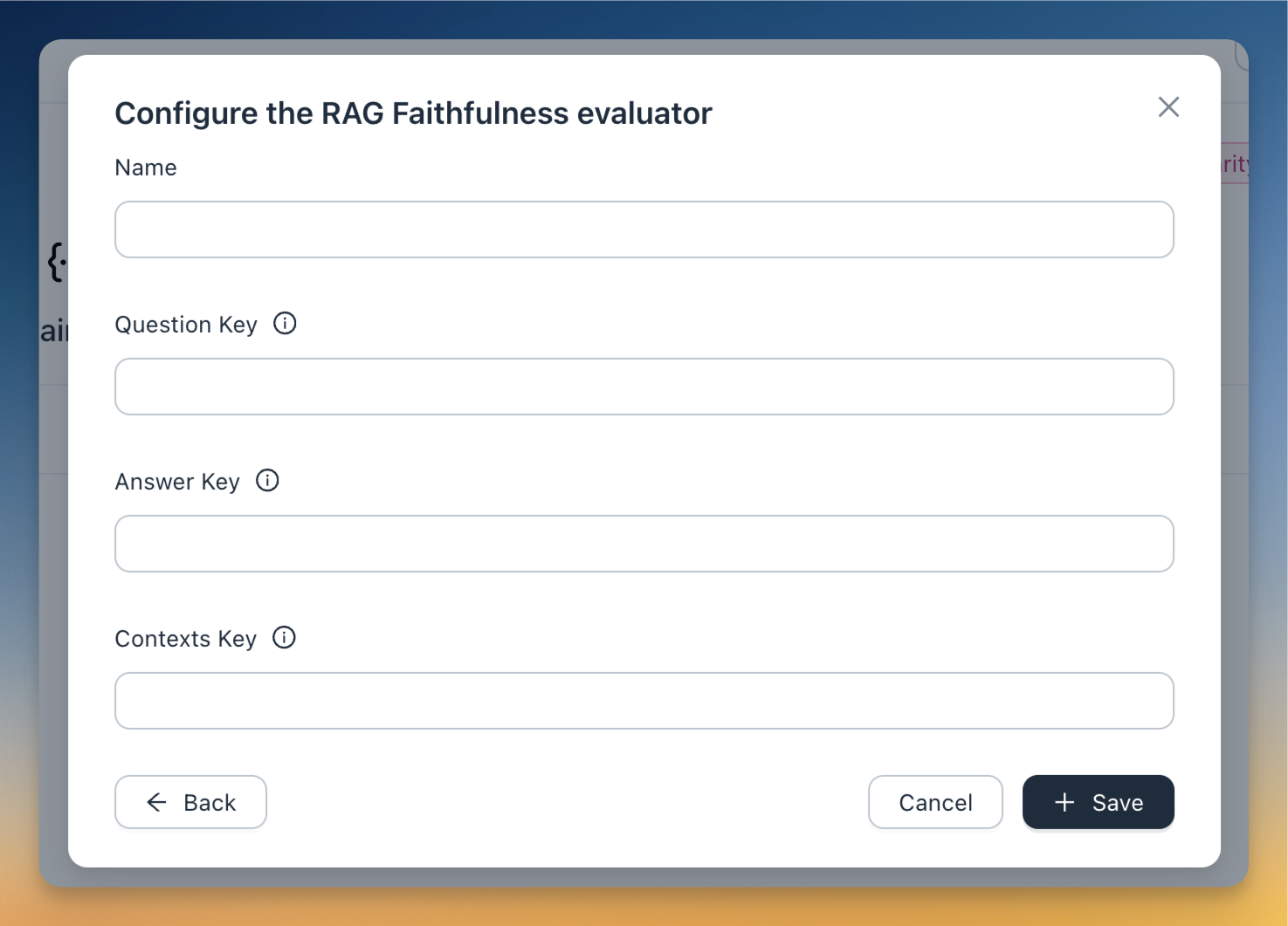
We've integrated RAGAS evaluators into agenta. Two new evaluators have been added: RAG Faithfulness (measuring how consistent the LLM output is with the context) and Context Relevancy (assessing how relevant the retrieved context is to the question). Both evaluators use intermediate outputs within the trace to calculate the final score.
Check out the tutorial to learn how to use RAG evaluators.
-
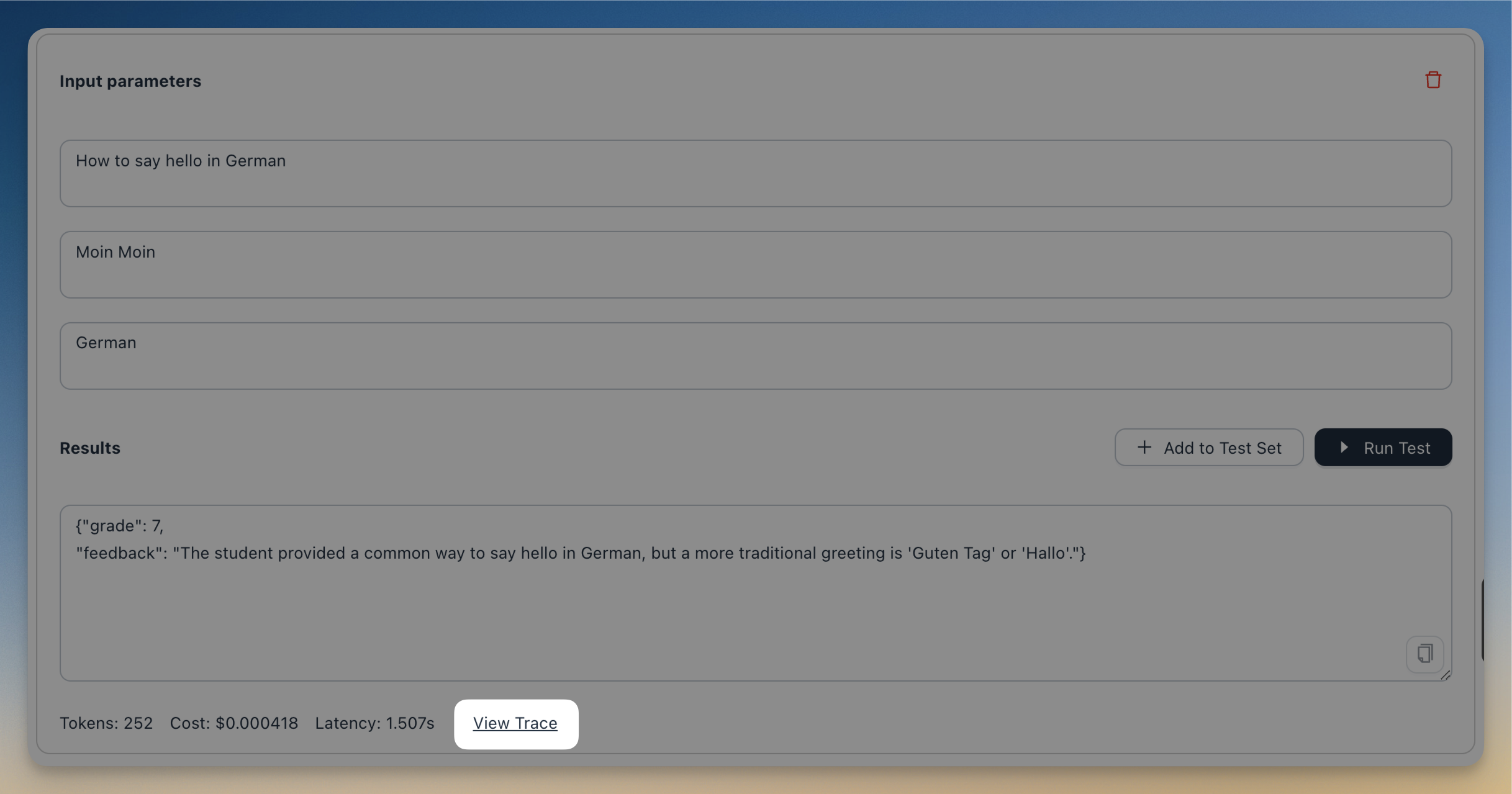
You can now view traces directly in the playground. This feature enables you to debug your application while configuring it—for example, by examining the prompts sent to the LLM or reviewing intermediate outputs.
Both features are available exclusively in the cloud and enterprise versions of agenta.
Migration from MongoDB to Postgres
9 July 2024
v0.19.0
We have migrated the Agenta database from MongoDB to Postgres. As a result, the platform is much more faster (up to 10x in some use cases).
However, if you are self-hosting agenta, note that this is a breaking change that requires you to manually migrate your data from MongoDB to Postgres. You can find more information how to migrate your data here.
If you are using the cloud version of Agenta, there is nothing you need to do (other than enjoying the new performance improvements).
More Reliable Evaluations
5 July 2024
v0.18.0
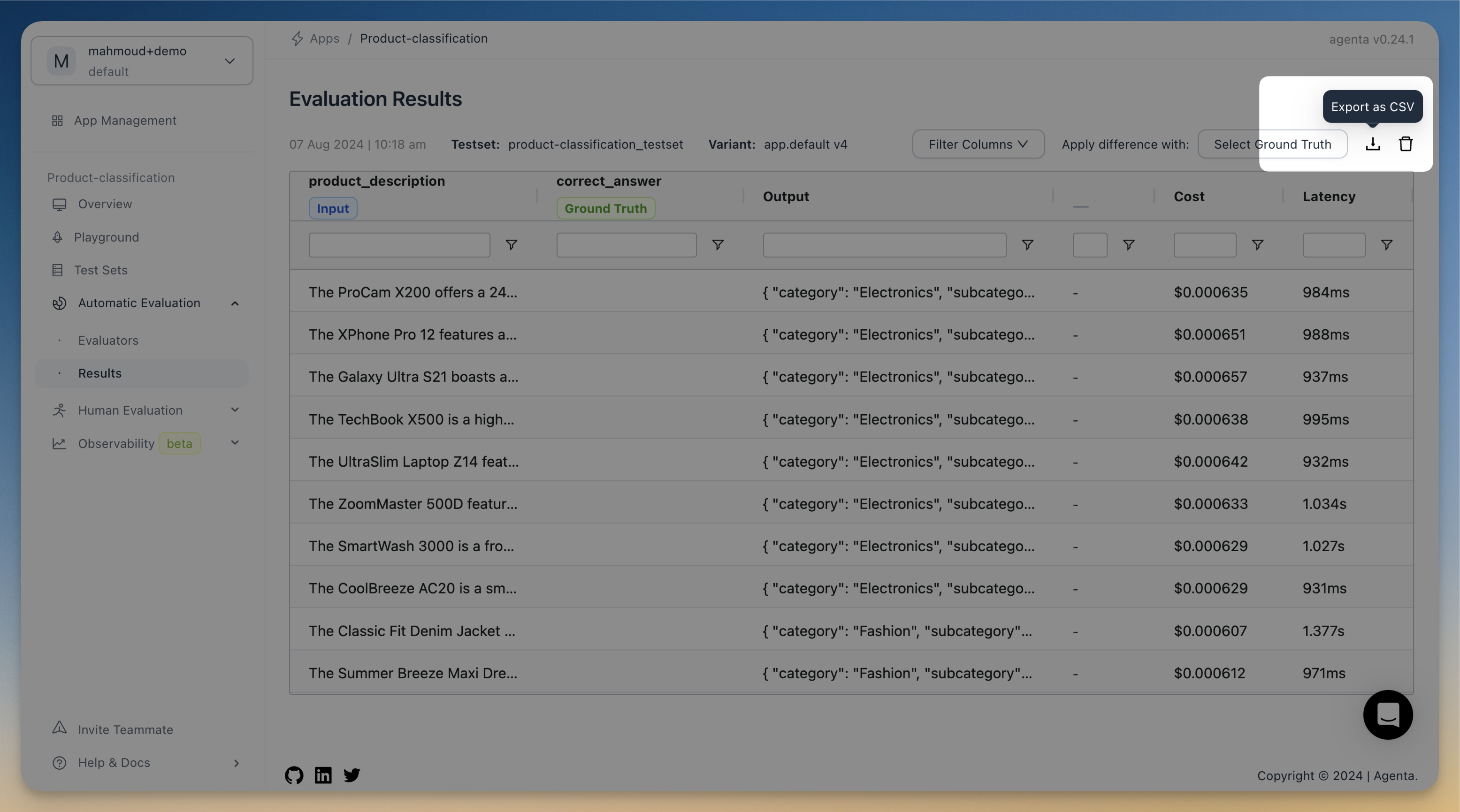
We have worked extensively on improving the reliability of evaluations. Specifically:
- We improved the status for evaluations and added a new
Queuedstatus - We improved the error handling in evaluations. Now we show the exact error message that caused the evaluation to fail.
- We fixed issues that caused evaluations to run infinitely
- We fixed issues in the calculation of scores in human evaluations.
- We fixed small UI issues with large output in human evaluations.
- We have added a new export button in the evaluation view to export the results as a CSV file.
Additionally, we have added a new Cookbook for run evaluation using the SDK.
In observability:
- We have added a new integration with Litellm to automatically trace all LLM calls done through it.
- Now we automatically propagate cost and token usage from spans to traces.
Evaluators can access all columns
4 June 2024
v0.17.0
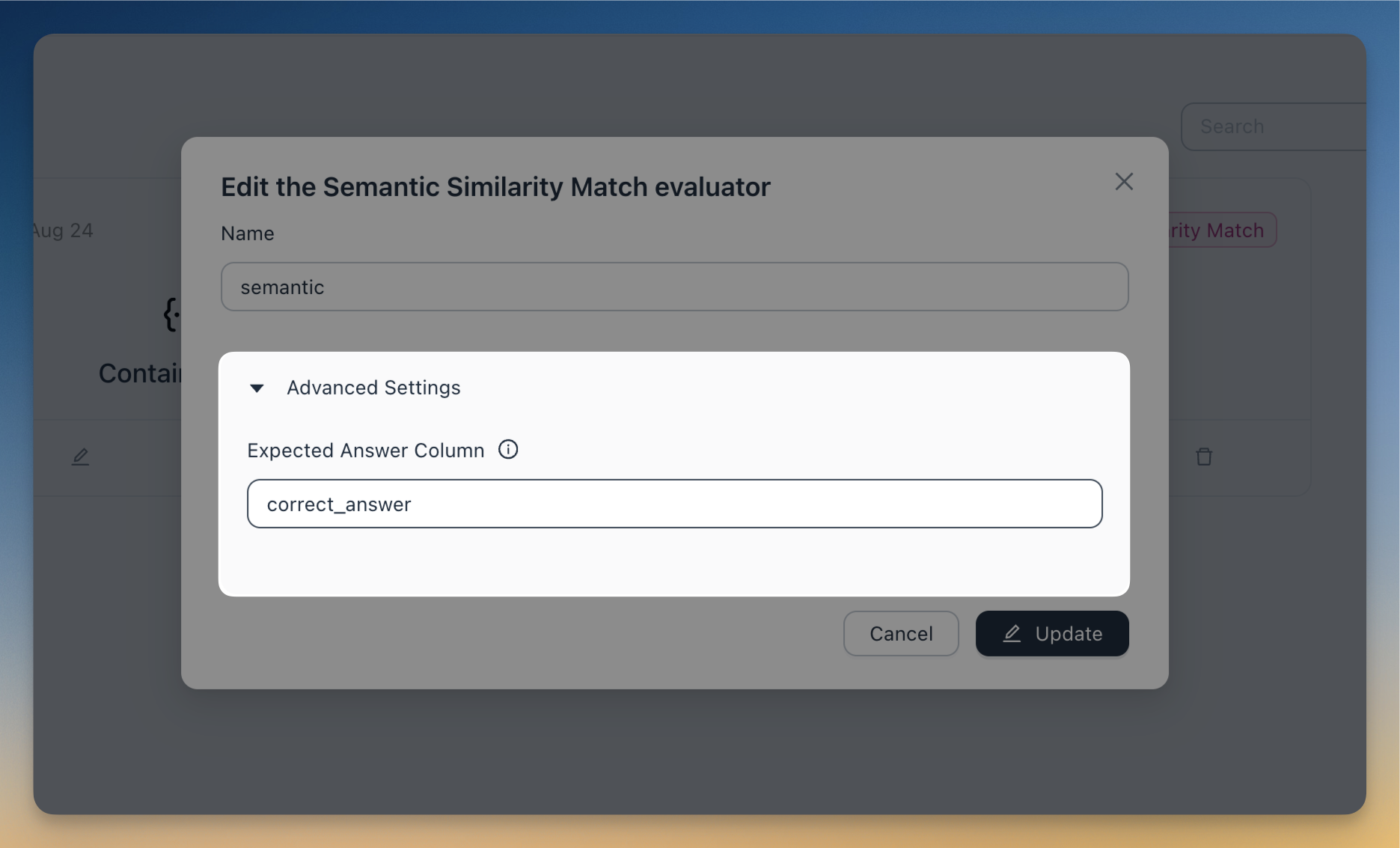
Evaluators now can access all columns in the test set. Previously, you were limited to using only the correct_answer column for the ground truth / reference answer in evaluation.
Now you can configure your evaluator to use any column in the test set as the ground truth. To do that, open the collapsable Advanced Settings when configuring the evaluator, and define the Expected Answer Column to the name of the columns containing the reference answer you want to use.
In addition to this:
- We've upgraded the SDK to pydantic v2.
- We have improved by 10x the speed for the get config endpoint
- We have add documentation for observability
New LLM Provider: Welcome Gemini!
25 May 2024
v0.14.14
We are excited to announce the addition of Google's Gemini to our list of supported LLM providers, bringing the total number to 12.
Playground Improvements
24 May 2024
v0.14.1-13
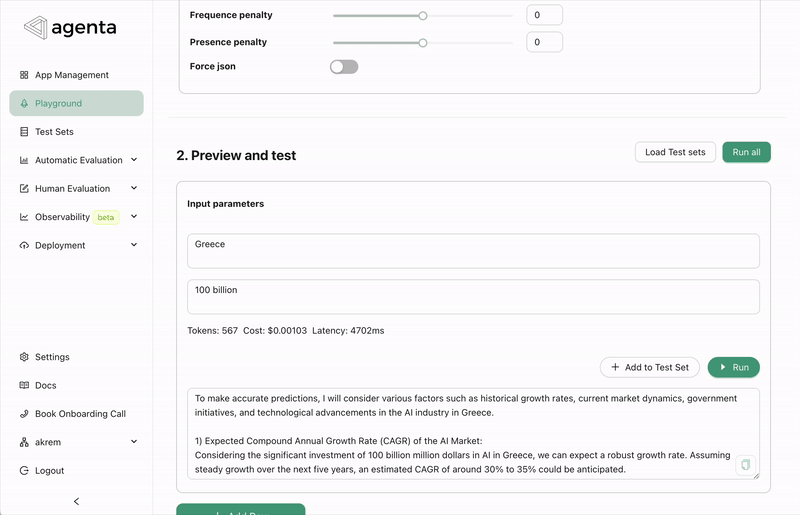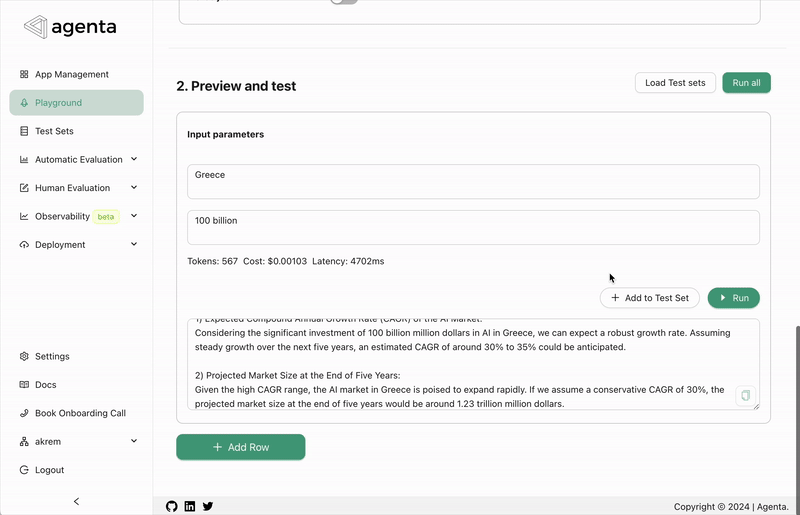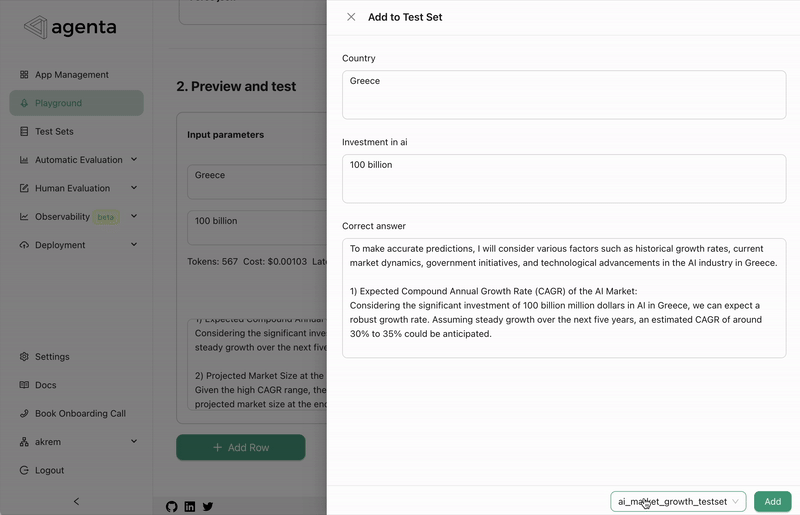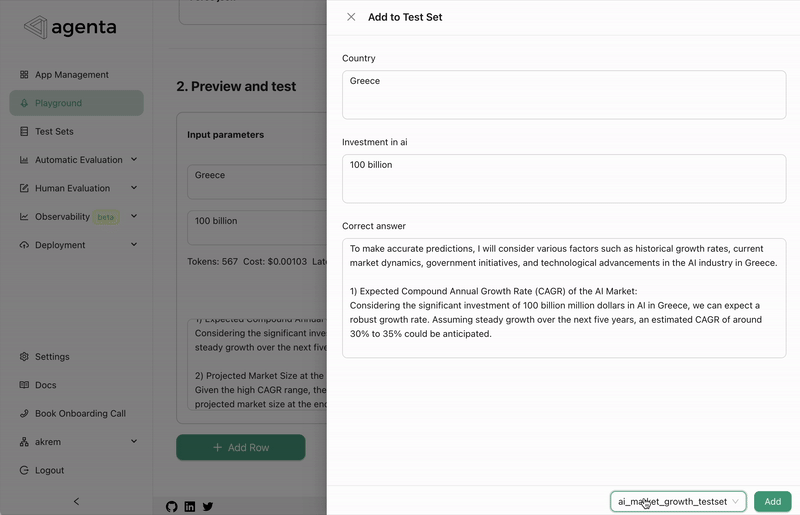
- We've improved the workflow for adding outputs to a dataset in the playground. In the past, you had to select the name of the test set each time. Now, the last used test set is selected by default..
- We have significantly improved the debugging experience when creating applications from code. Now, if an application fails, you can view the logs to understand the reason behind the failure.
- We moved the copy message button in the playground to the output text area.
- We now hide the cost and usage in the playground when they aren't specified
- We've made improvements to error messages in the playground
Bug Fixes
- Fixed the order of the arguments when running a custom code evaluator
- Fixed the timestamp in the Testset view (previous stamps was droppping the trailing 0)
- Fixed the creation of application from code in the self-hosted version when using Windows
Prompt and Configuration Registry
1 May 2024
v0.14.0
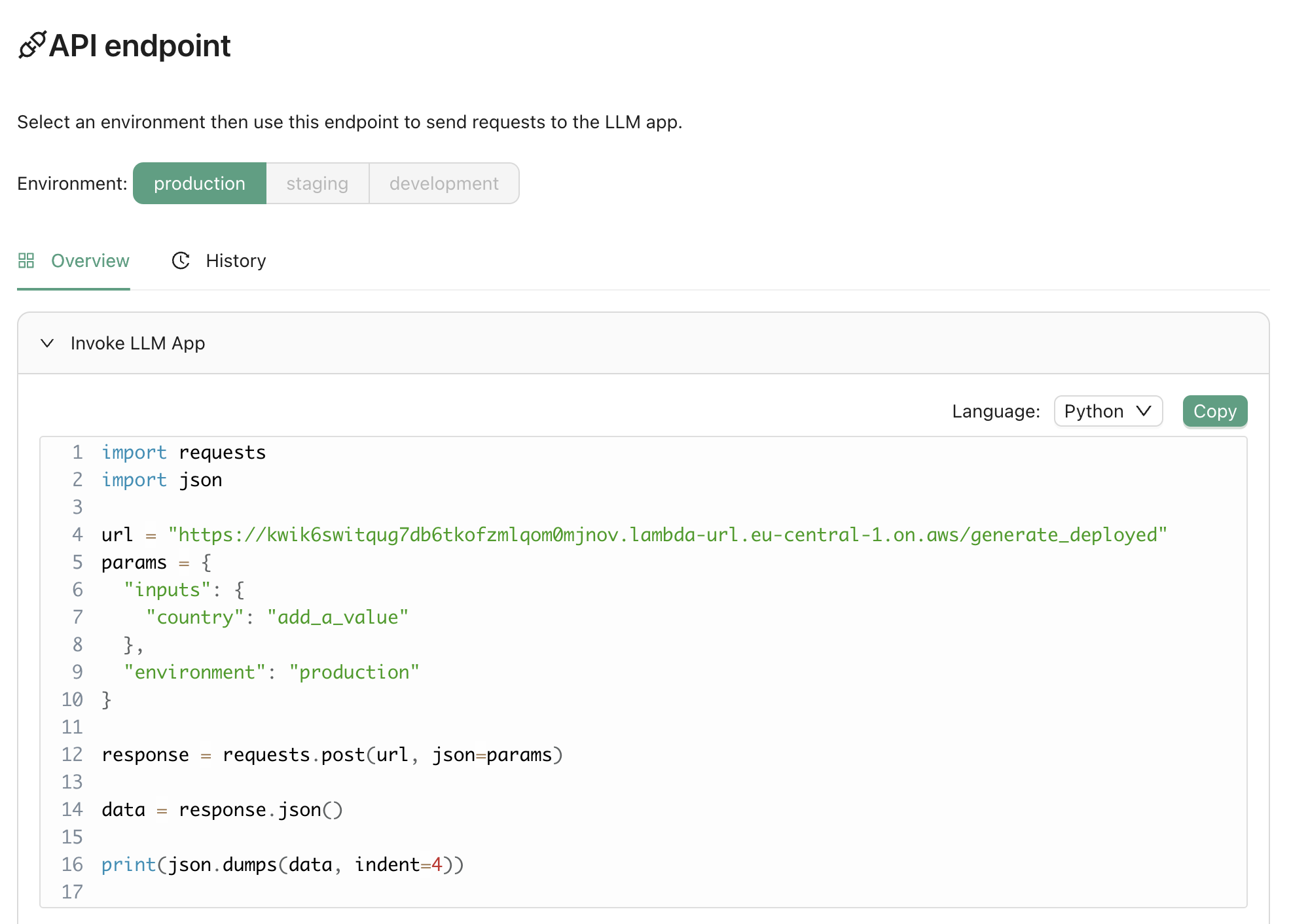
We've introduced a feature that allows you to use Agenta as a prompt registry or management system. In the deployment view, we now provide an endpoint to directly fetch the latest version of your prompt. Here is how it looks like:
from agenta import Agenta
agenta = Agenta()
config = agenta.get_config(base_id="xxxxx", environment="production", cache_timeout=200) # Fetches the configuration with caching
You can find additional documentation here.
Improvements
- Previously, publishing a variant from the playground to an environment was a manual process., from now on we are publishing by default to the production environment.
Miscellaneous Improvements
28 April 2024
v0.13.8
- The total cost of an evaluation is now displayed in the evaluation table. This allows you to understand how much evaluations are costing you and track your expenses.

Bug Fixes
- Fixed sidebar focus in automatic evaluation results view
- Fix the incorrect URLs shown when running agenta variant serve
Evaluation Speed Increase and Numerous Quality of Life Improvements
23rd April 2024
v0.13.1-5
- We've improved the speed of evaluations by 3x through the use of asynchronous batching of calls.
- We've added Groq as a new provider along with Llama3 to our playground.
Bug Fixes
- Resolved a rendering UI bug in Testset view.
- Fixed incorrect URLs displayed when running the 'agenta variant serve' command.
- Corrected timestamps in the configuration.
- Resolved errors when using the chat template with empty input.
- Fixed latency format in evaluation view.
- Added a spinner to the Human Evaluation results table.
- Resolved an issue where the gitignore was being overwritten when running 'agenta init'.
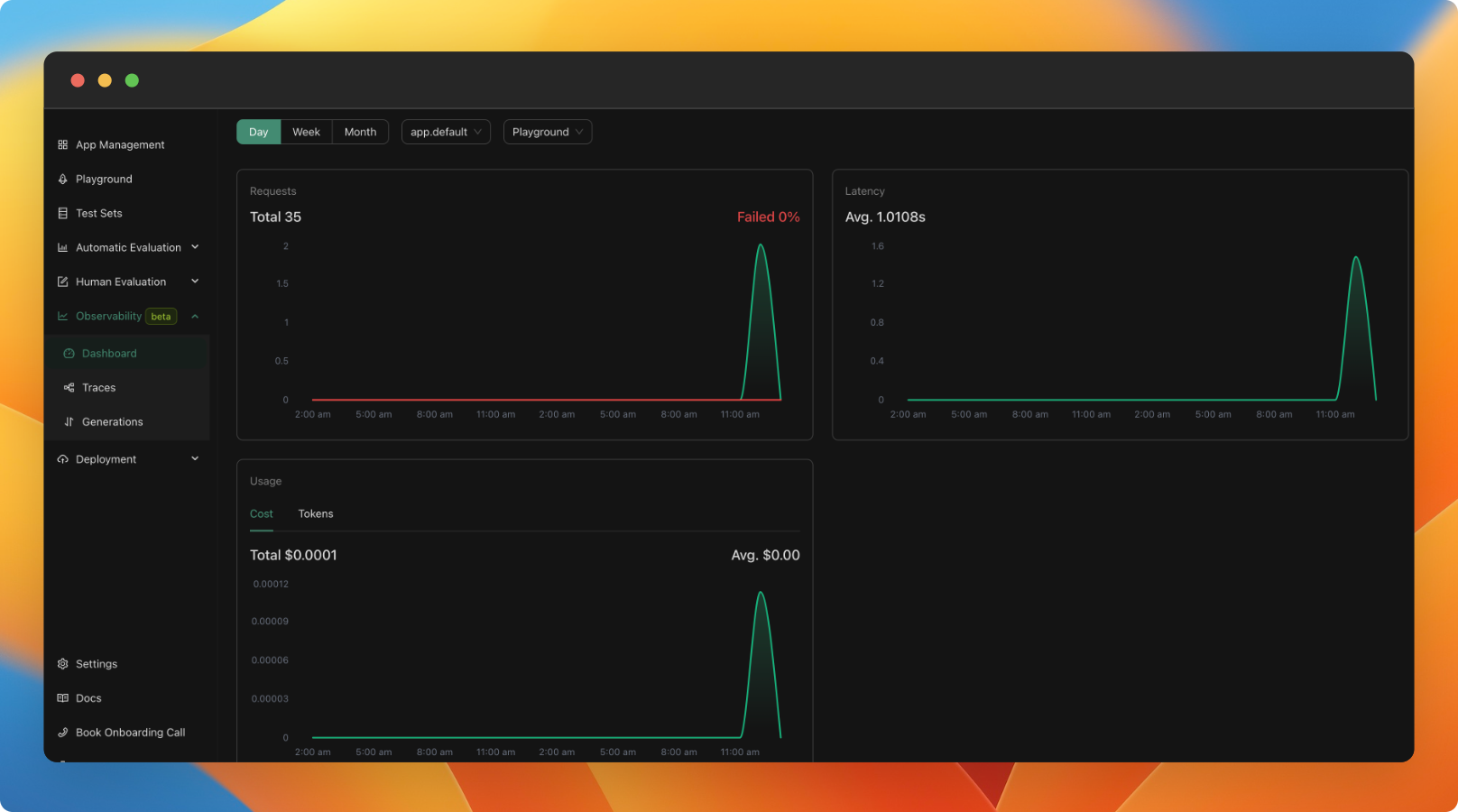
Observability (beta)
14th April 2024
v0.13.0
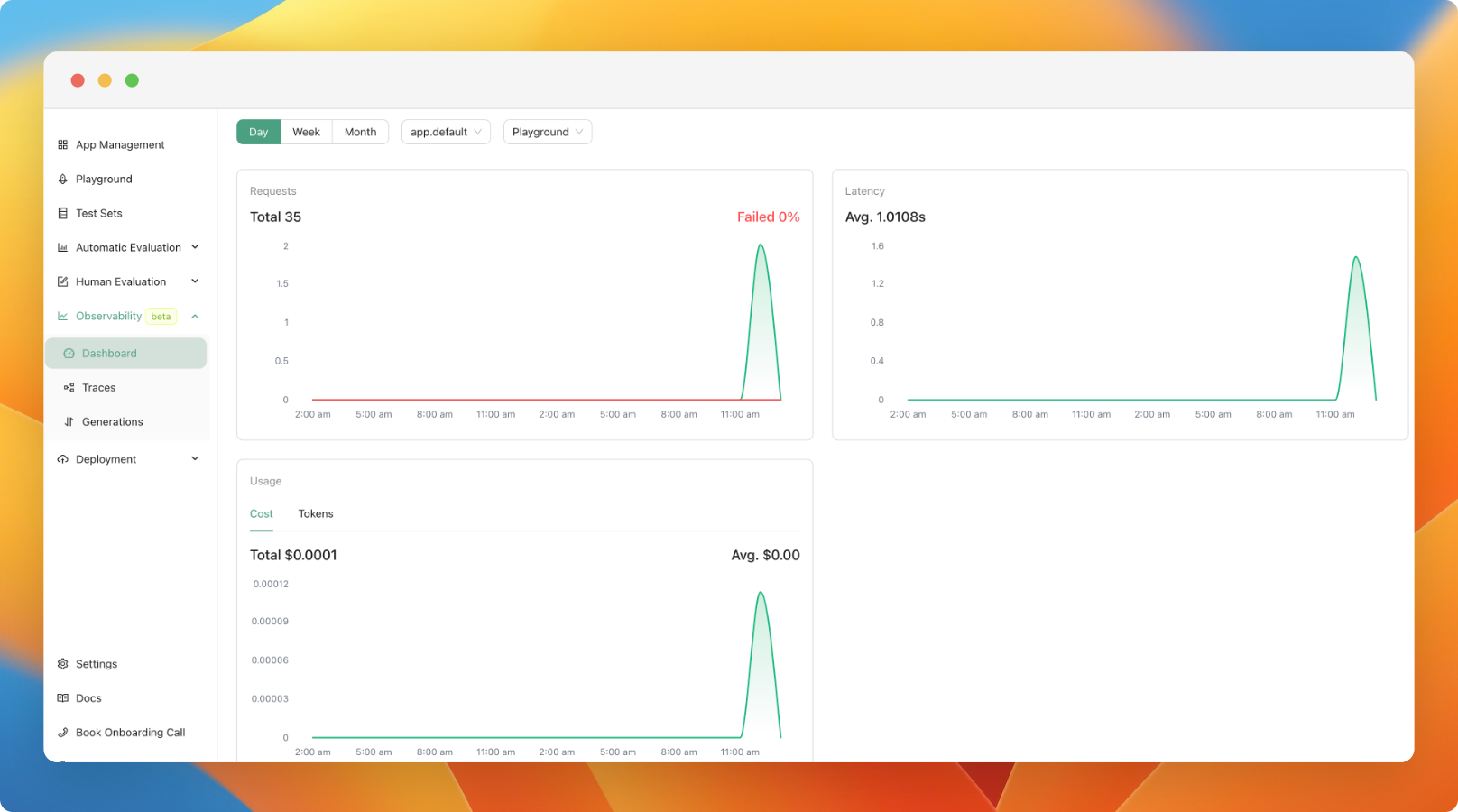
You can now monitor your application usage in production. We've added a new observability feature (currently in beta), which allows you to:
- Monitor cost, latency, and the number of calls to your applications in real-time.
- View the logs of your LLM calls, including inputs, outputs, and used configurations. You can also add any interesting logs to your test set.
- Trace your more complex LLM applications to understand the logic within and debug it.
As of now, all new applications created will include observability by default. We are working towards a GA version in the next weeks, which will be scalable and better integrated with your applications. We will also be adding tutorials and documentation about it.
Find examples of LLM apps created from code with observability here.
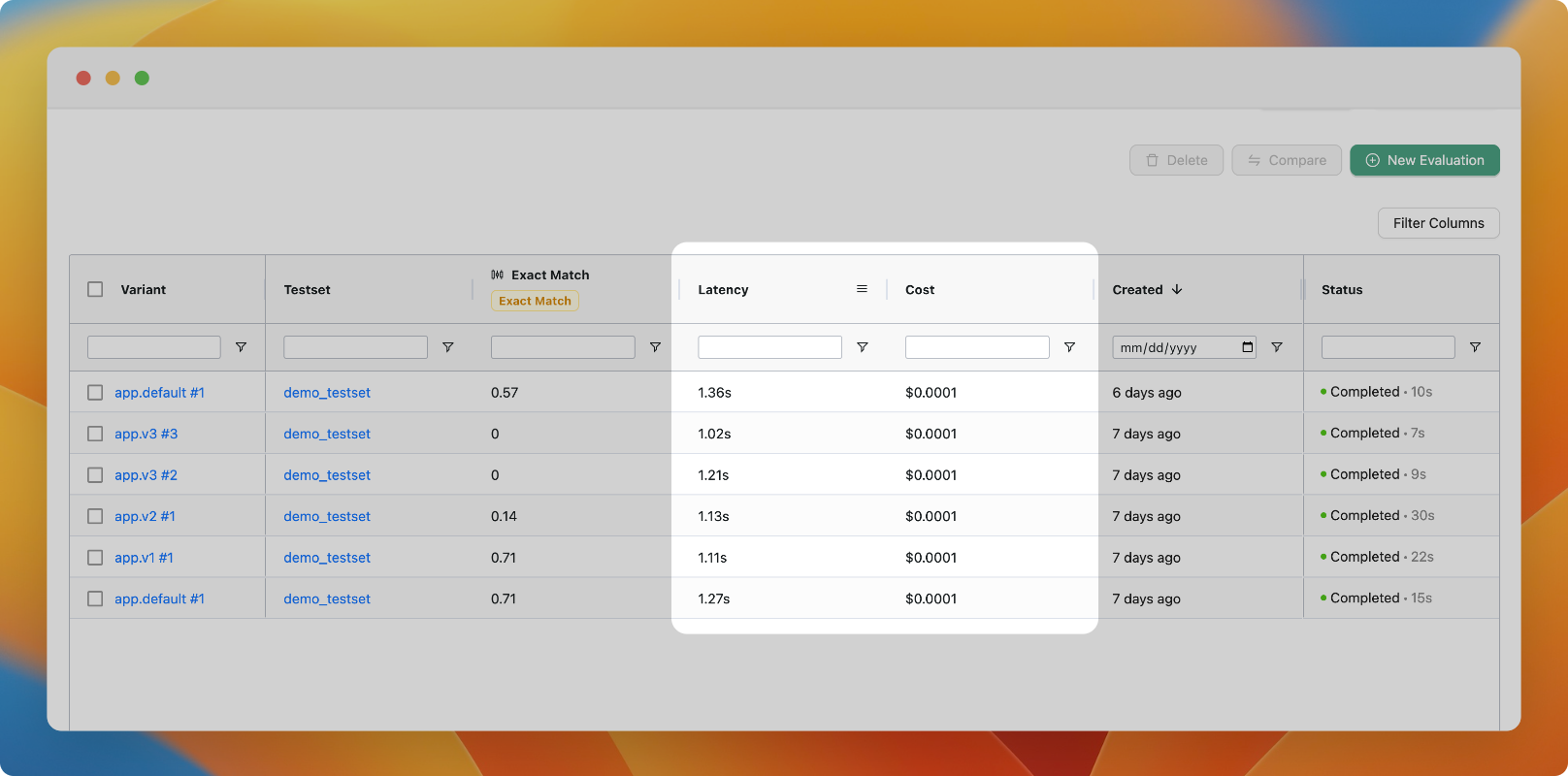
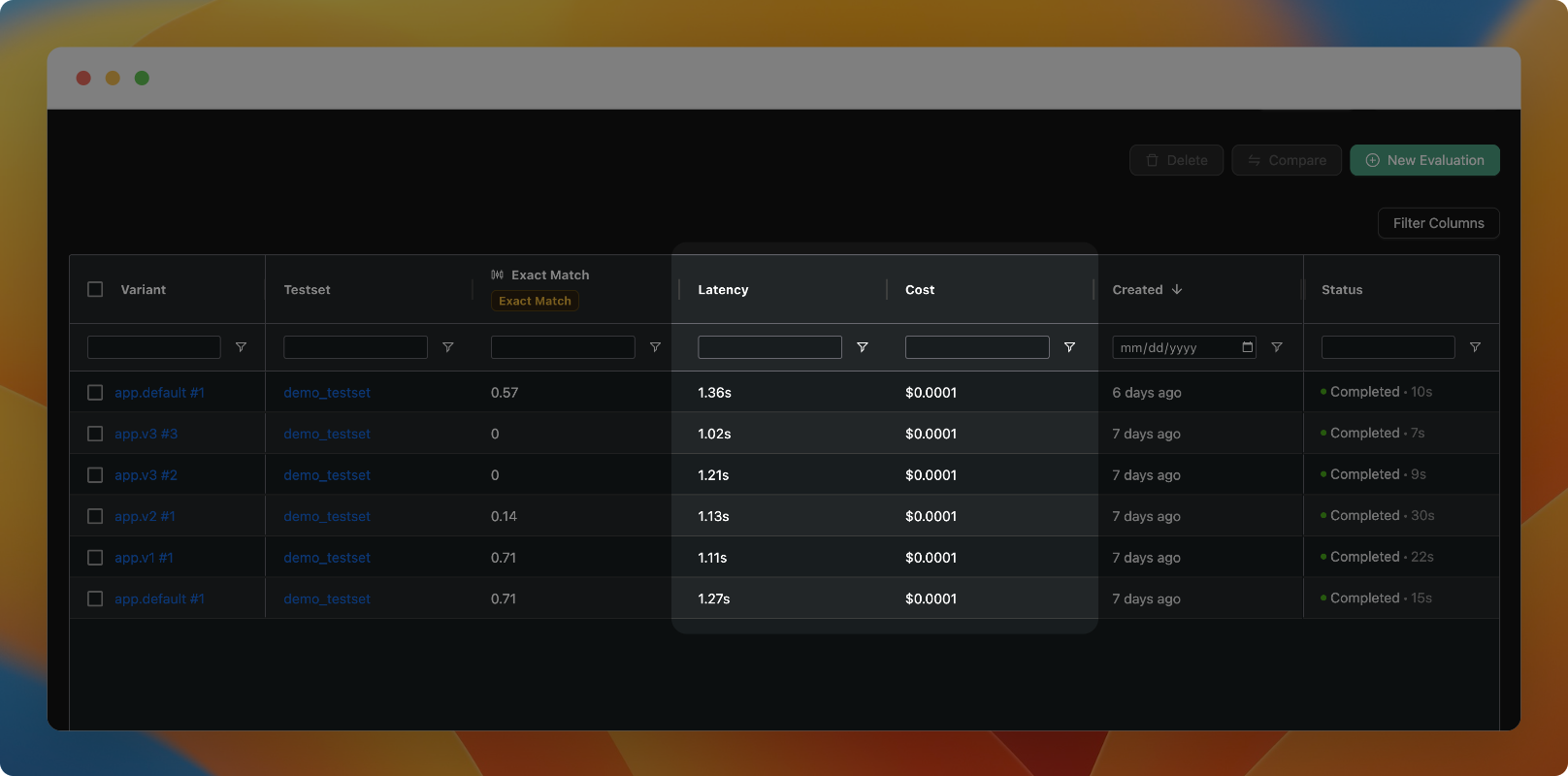
Compare latency and costs
1st April 2024
v0.12.6
You can now compare the latency and cost of different variants in the evaluation view.
Minor improvements
31st March 2024
v0.12.5
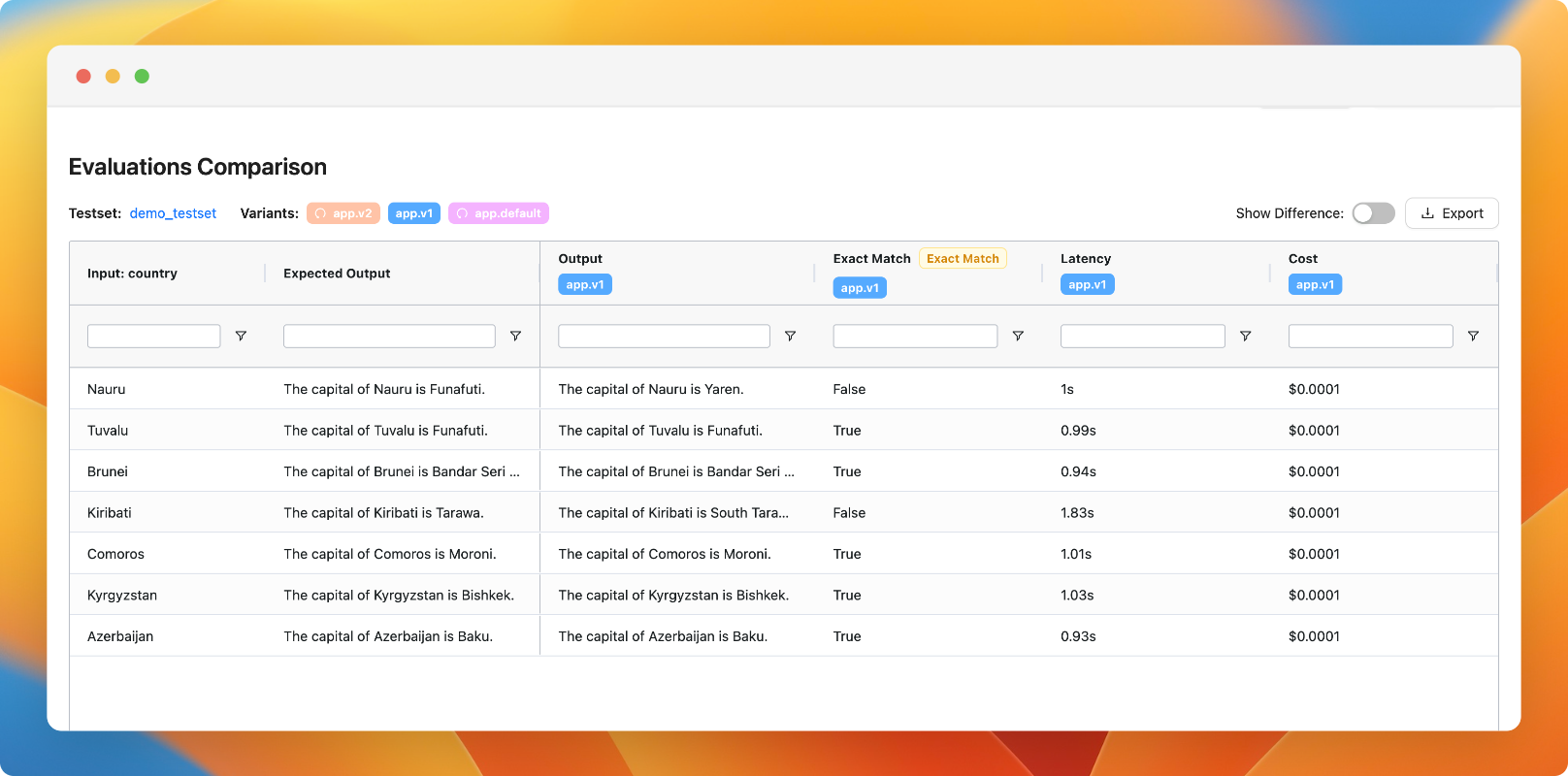
Toggle variants in comparison view
You can now toggle the visibility of variants in the comparison view, allowing you to compare a multitude of variants side-by-side at the same time.
Improvements
- You can now add a datapoint from the playground to the test set even if there is a column mismatch
Bug fixes
- Resolved issue with "Start Evaluation" button in Testset view
- Fixed bug in CLI causing variant not to serve
New evaluators
25th March 2024
v0.12.4
We have added some more evaluators, a new string matching and a Levenshtein distance evaluation.
Improvements
- Updated documentation for human evaluation
- Made improvements to Human evaluation card view
- Added dialog to indicate testset being saved in UI
Bug fixes
- Fixed issue with viewing the full output value during evaluation
- Enhanced error boundary logic to unblock user interface
- Improved logic to save and retrieve multiple LLM provider keys
- Fixed Modal instances to support dark mode
Minor improvements
11th March 2024
v0.12.3
- Improved the logic of the Webhook evaluator
- Made the inputs in the Human evaluation view non-editable
- Added an option to save a test set in the Single model evaluation view
- Included the evaluator name in the "Configure your evaluator" modal
Bug fixes
- Fixed column resize in comparison view
- Resolved a bug affecting the evaluation output in the CSV file
- Corrected the path to the Evaluators view when navigating from Evaluations
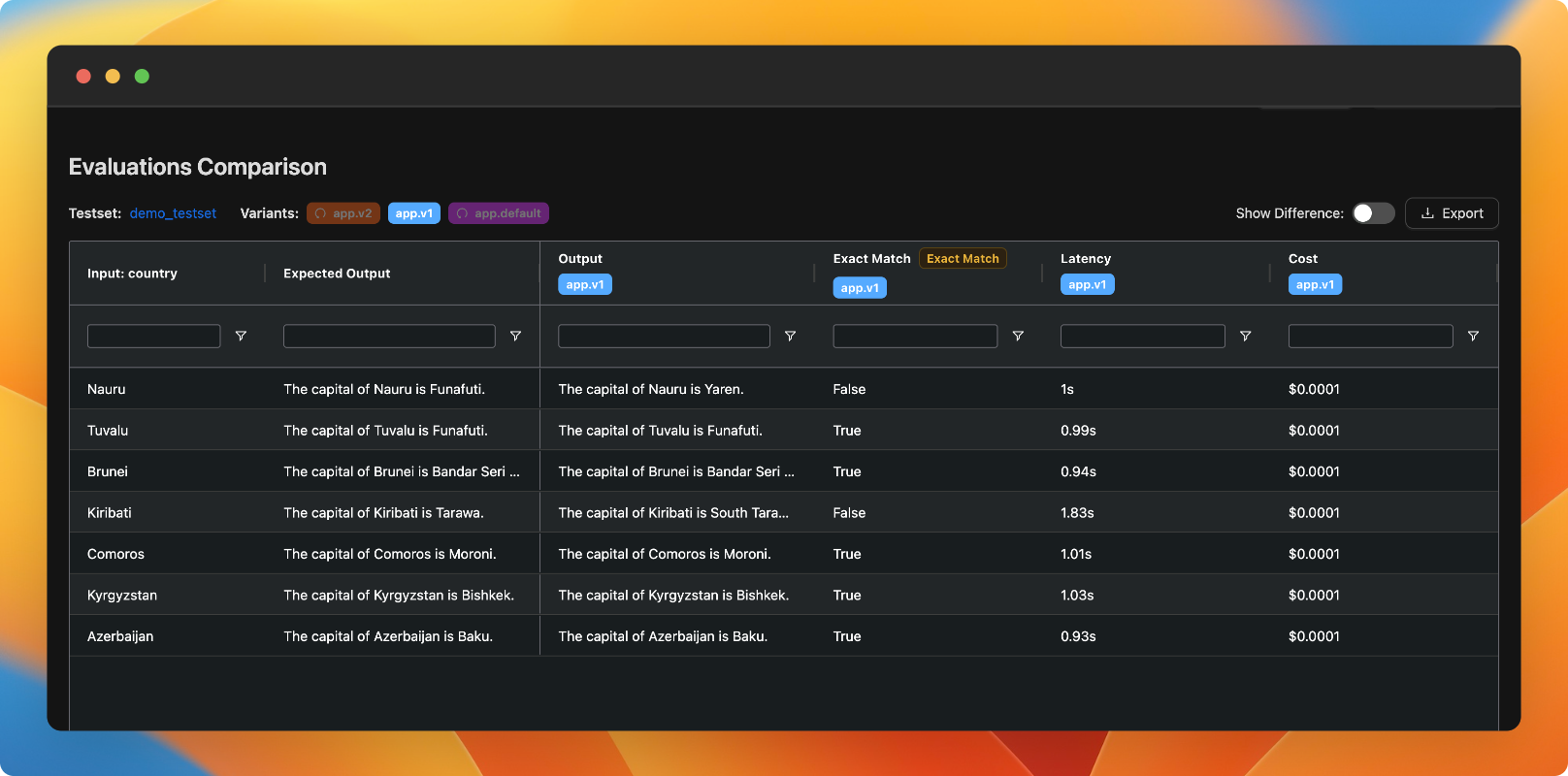
Highlight ouput difference when comparing evaluations
4th March 2024
v0.12.2
We have improved the evaluation comparison view to show the difference to the expected output.
Improvements
- Improved the error messages when invoking LLM applications
- Improved "Add new evaluation" modal
- Upgraded Sidemenu to display Configure evaluator and run evaluator under Evaluations section
- Changed cursor to pointer when hovering over evaluation results
Deployment Versioning and RBAC
14th February 2024
v0.12.0
Deployment versioning
You now have access to a history of prompts deployed to our three environments. This feature allows you to roll back to previous versions if needed.
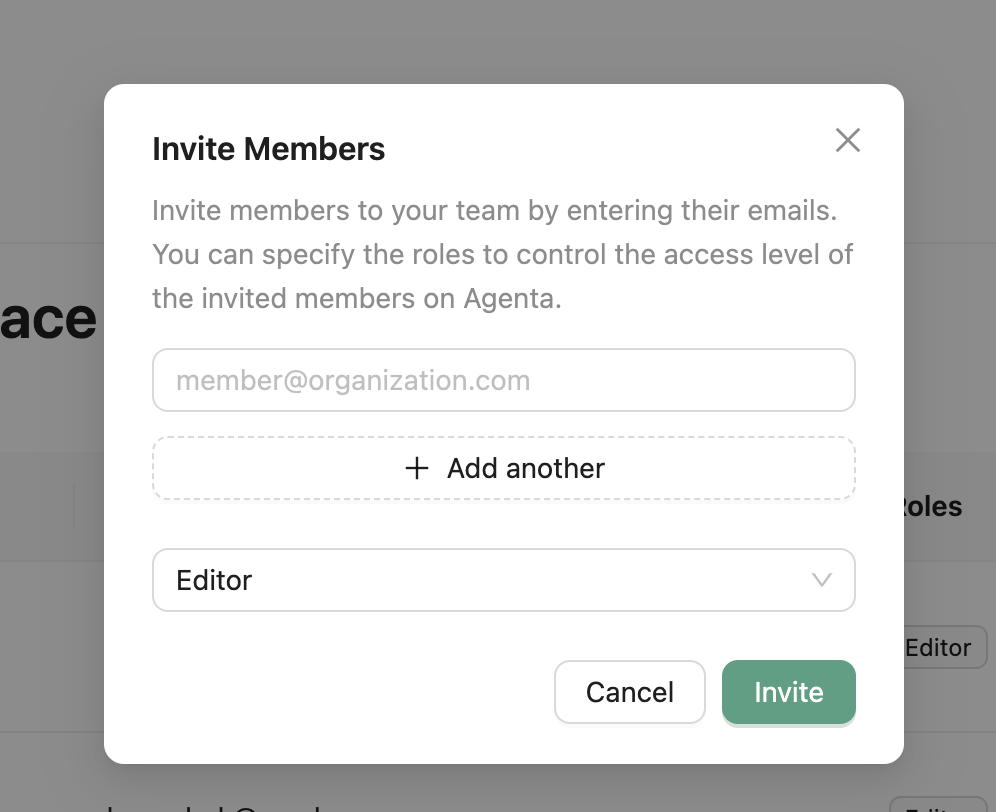
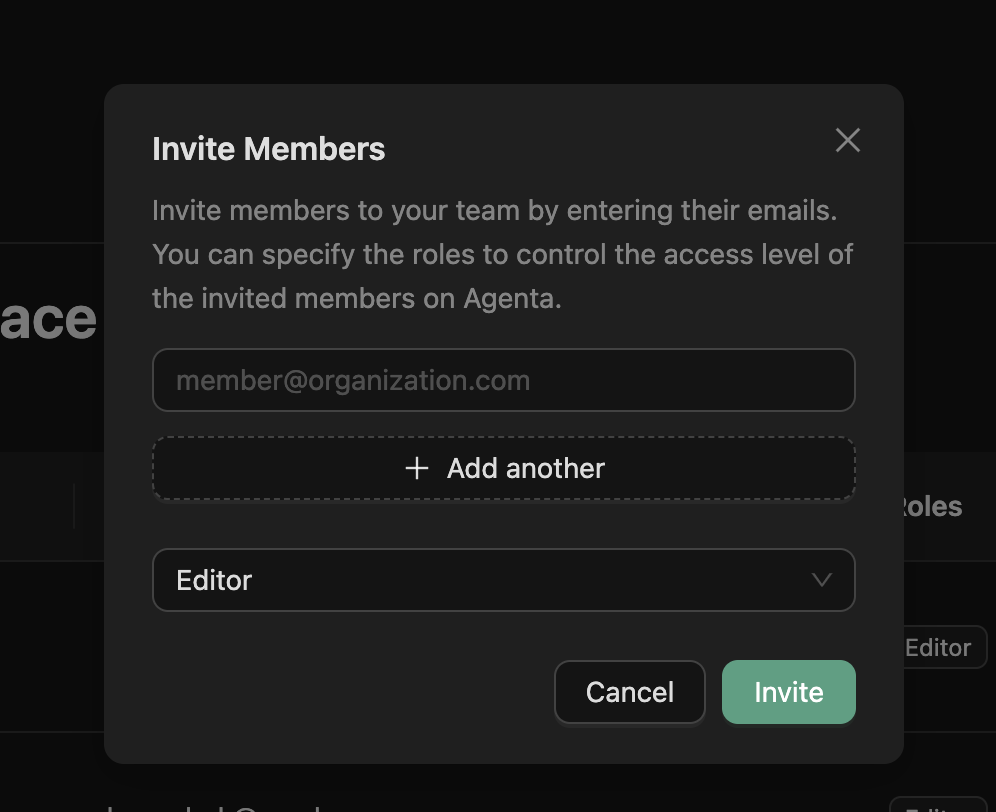
Role-Based Access Control
You can now invite team members and assign them fine-grained roles in agenta.
Improvements
- We now prevent the deletion of test sets that are used in evaluations
Bug fixes
-
Fixed bug in custom code evaluation aggregation. Up until know the aggregated result for custom code evalution where not computed correctly.
-
Fixed bug with Evaluation results not being exported correctly
-
Updated documentation for vision gpt explain images
-
Improved Frontend test for Evaluations
Minor fixes
4th February 2024
v0.10.2
- Addressed issue when invoking LLM app with missing LLM provider key
- Updated LLM providers in Backend enum
- Fixed bug in variant environment deployment
- Fixed the sorting in evaluation tables
- Made use of server timezone instead of UTC
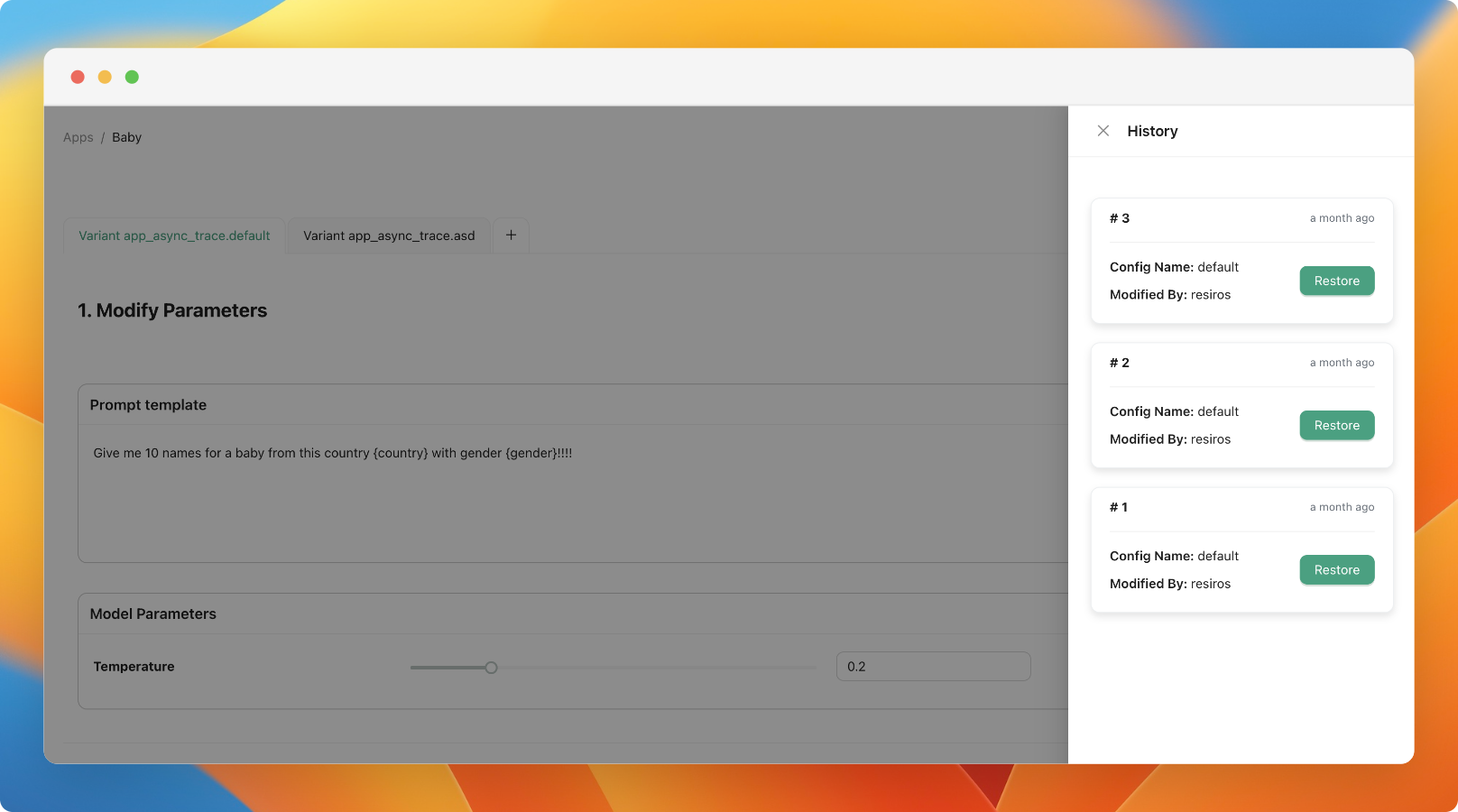
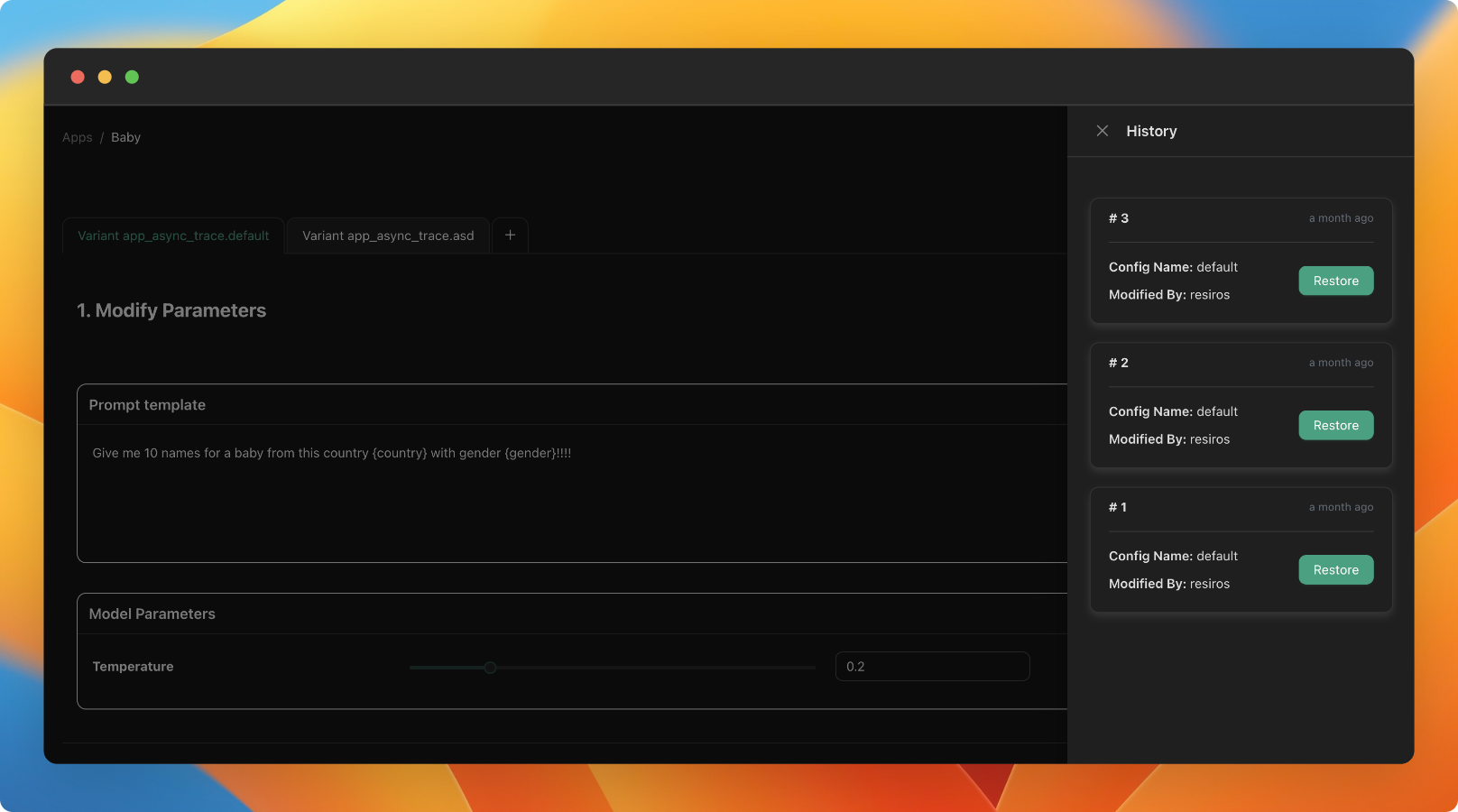
Prompt Versioning
31st January 2024
v0.10.0
We've introduced the feature to version prompts, allowing you to track changes made by the team and revert to previous versions. To view the change history of the configuration, click on the sign in the playground to access all previous versions.
New JSON Evaluator
30th January 2024
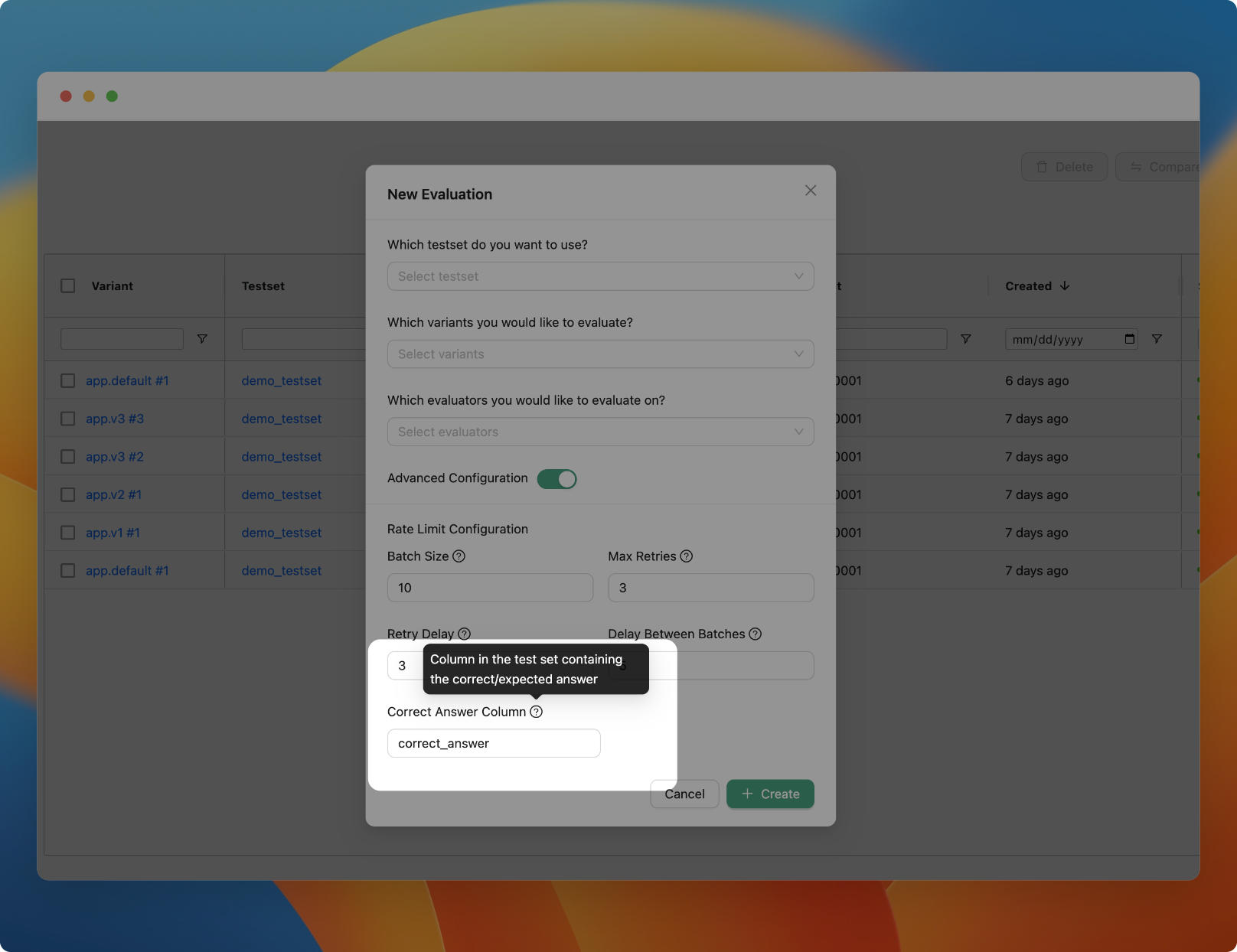
v0.9.1
We have added a new evaluator to match JSON fields and added the possiblity to use other columns in the test set other than the correct_answer column as the ground truth.
Improved error handling in evaluation
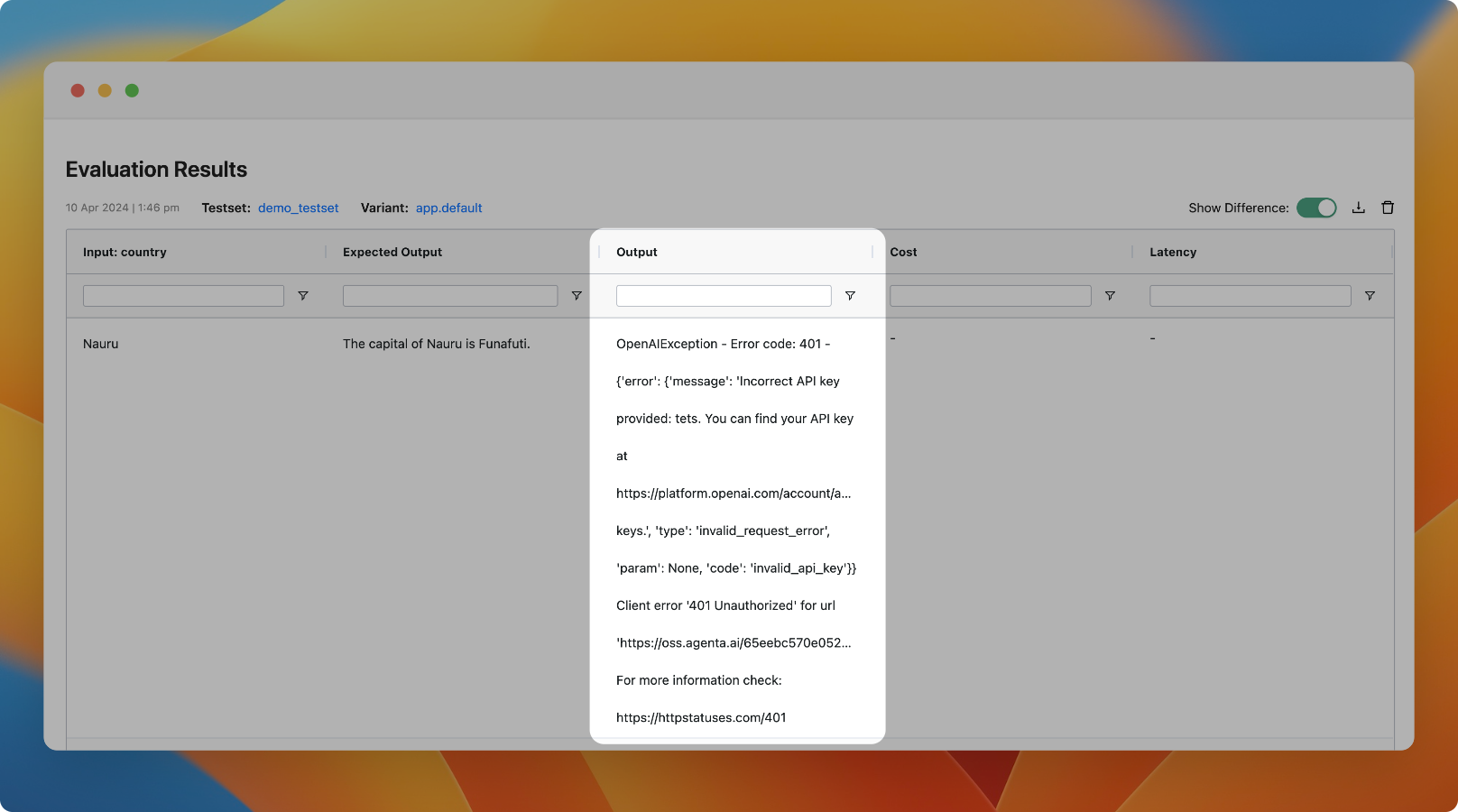
29th January 2024
v0.9.0
We have improved error handling in evaluation to return more information about the exact source of the error in the evaluation view.
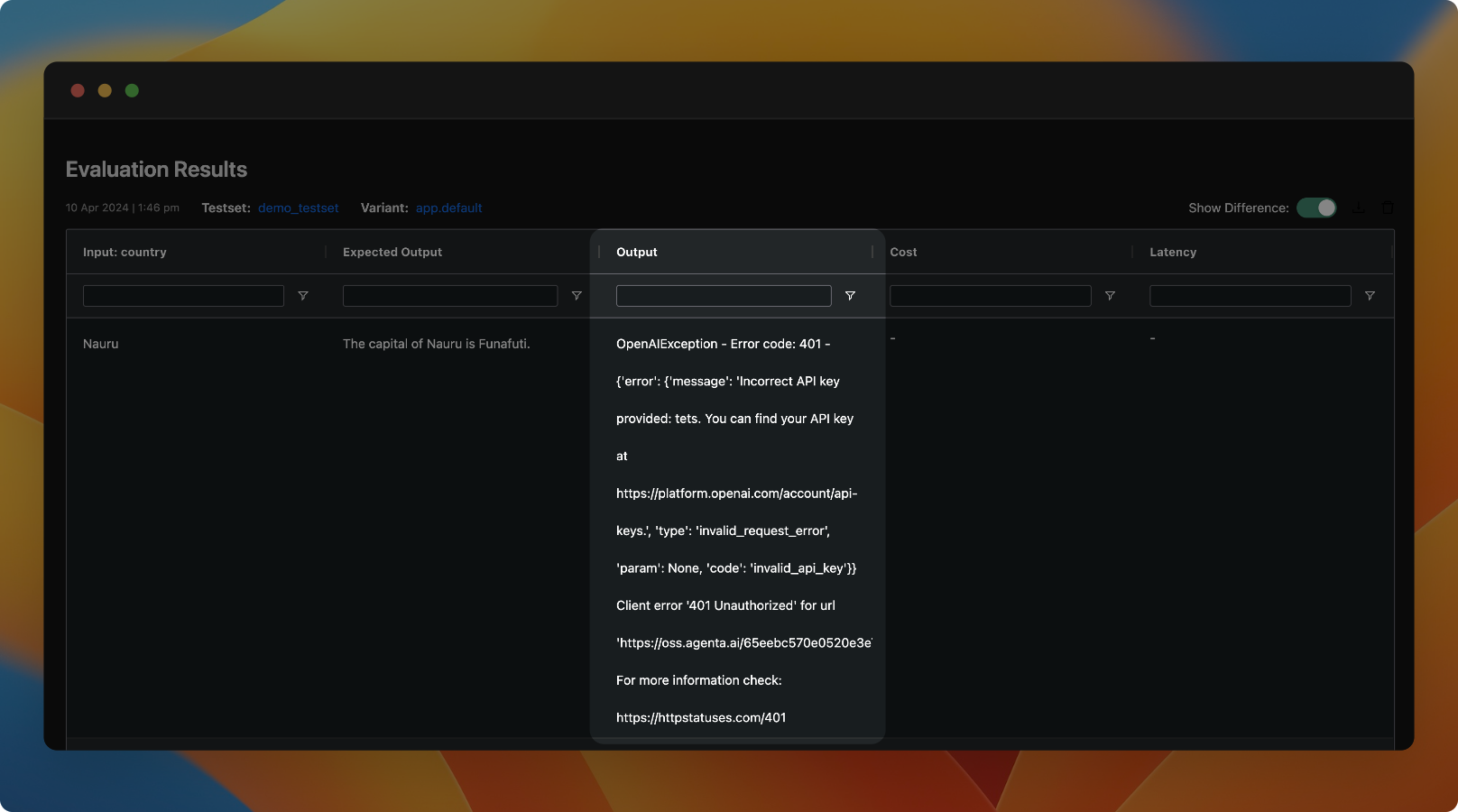
Improvements:
- Added the option in A/B testing human evaluation to mark both variants as correct
- Improved loading state in Human Evaluation
Bring your own API key
25th January 2024
v0.8.3
Up until know, we required users to use our OpenAI API key when using cloud. Starting now, you can use your own API key for any new application you create.
Improved human evaluation workflow
24th January 2024
v0.8.2
Faster human evaluation workflow
We have updated the human evaluation table view to add annotation and correct answer columns.
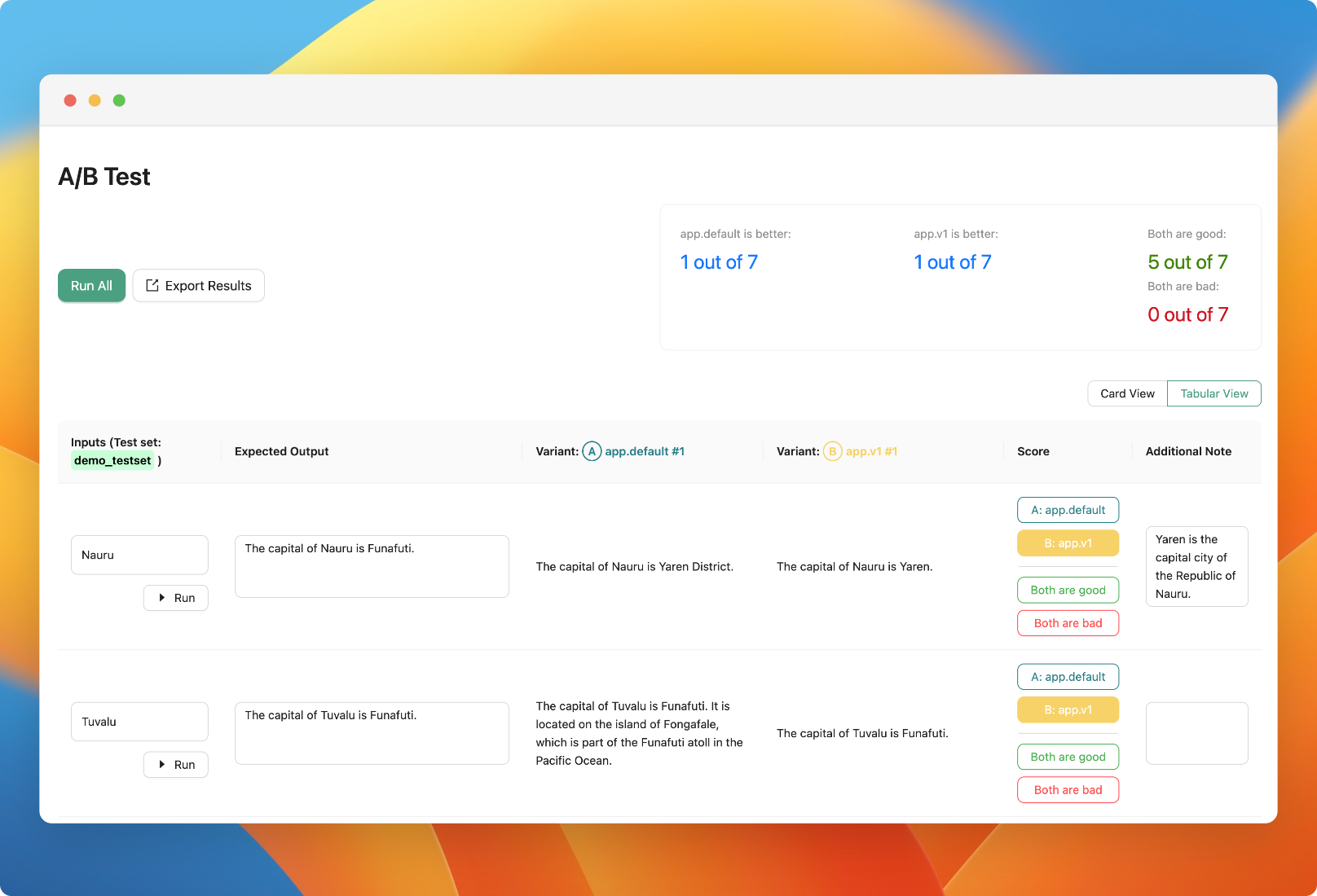
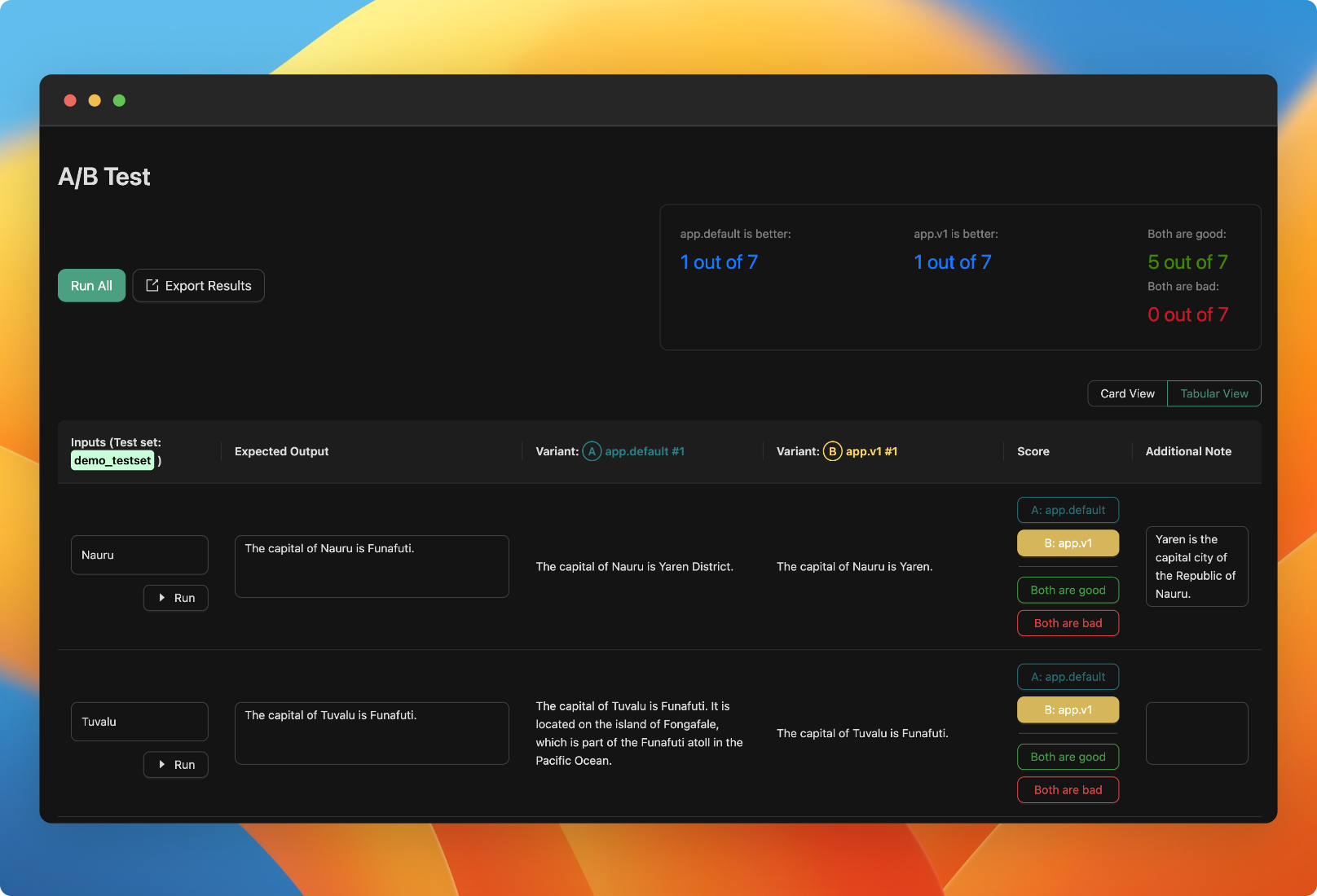
Improvements:
- Simplified the database migration process
- Fixed environment variable injection to enable cloud users to use their own keys
- Disabled import from endpoint in cloud due to security reasons
- Improved query lookup speed for evaluation scenarios
- Improved error handling in playground
Bug fixes:
- Resolved failing Backend tests
- Fixed a bug in rate limit configuration validation
- Fixed issue with all aggregated results
- Resolved issue with live results in A/B testing evaluation not updating
Revamping evaluation
22nd January 2024
v0.8.0
We've spent the past month re-engineering our evaluation workflow. Here's what's new:
Running Evaluations
- Simultaneous Evaluations: You can now run multiple evaluations for different app variants and evaluators concurrently.
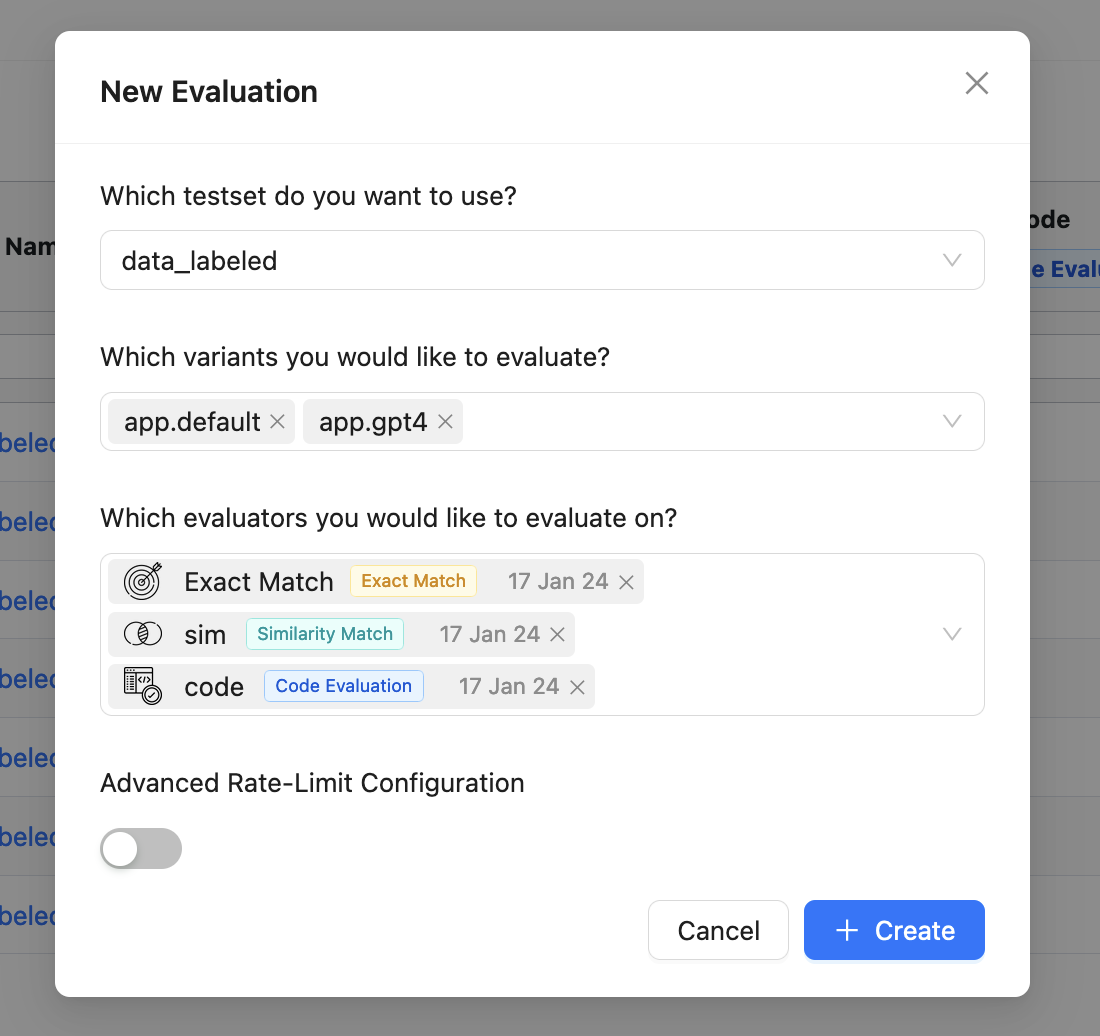
- Rate Limit Parameters: Specify these during evaluations and reattempts to ensure reliable results without exceeding open AI rate limits.
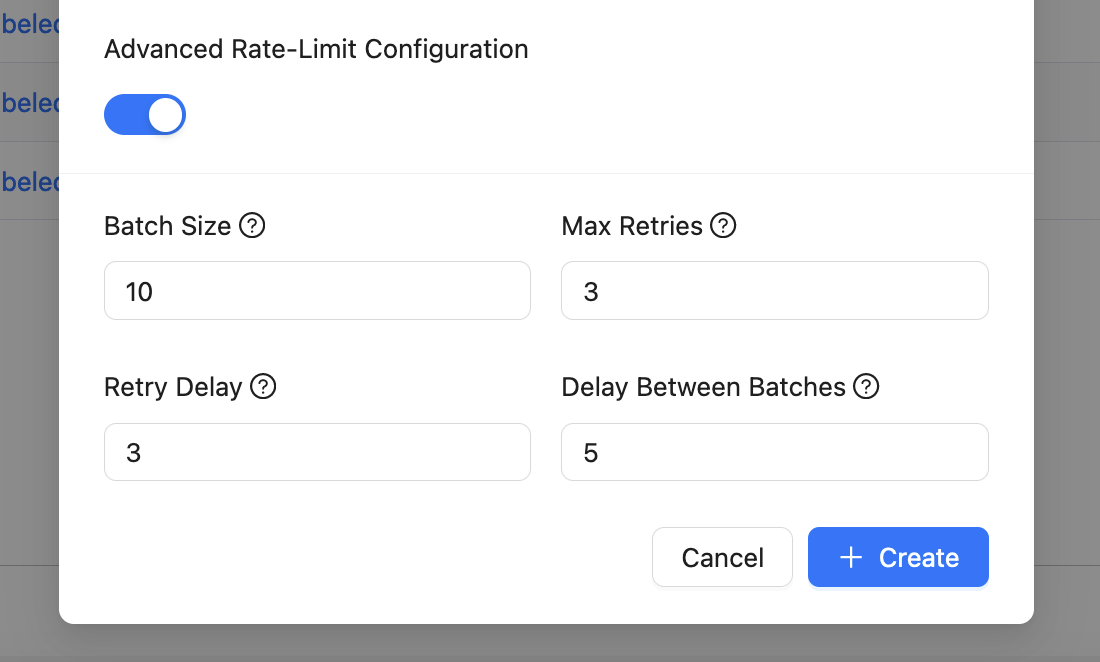
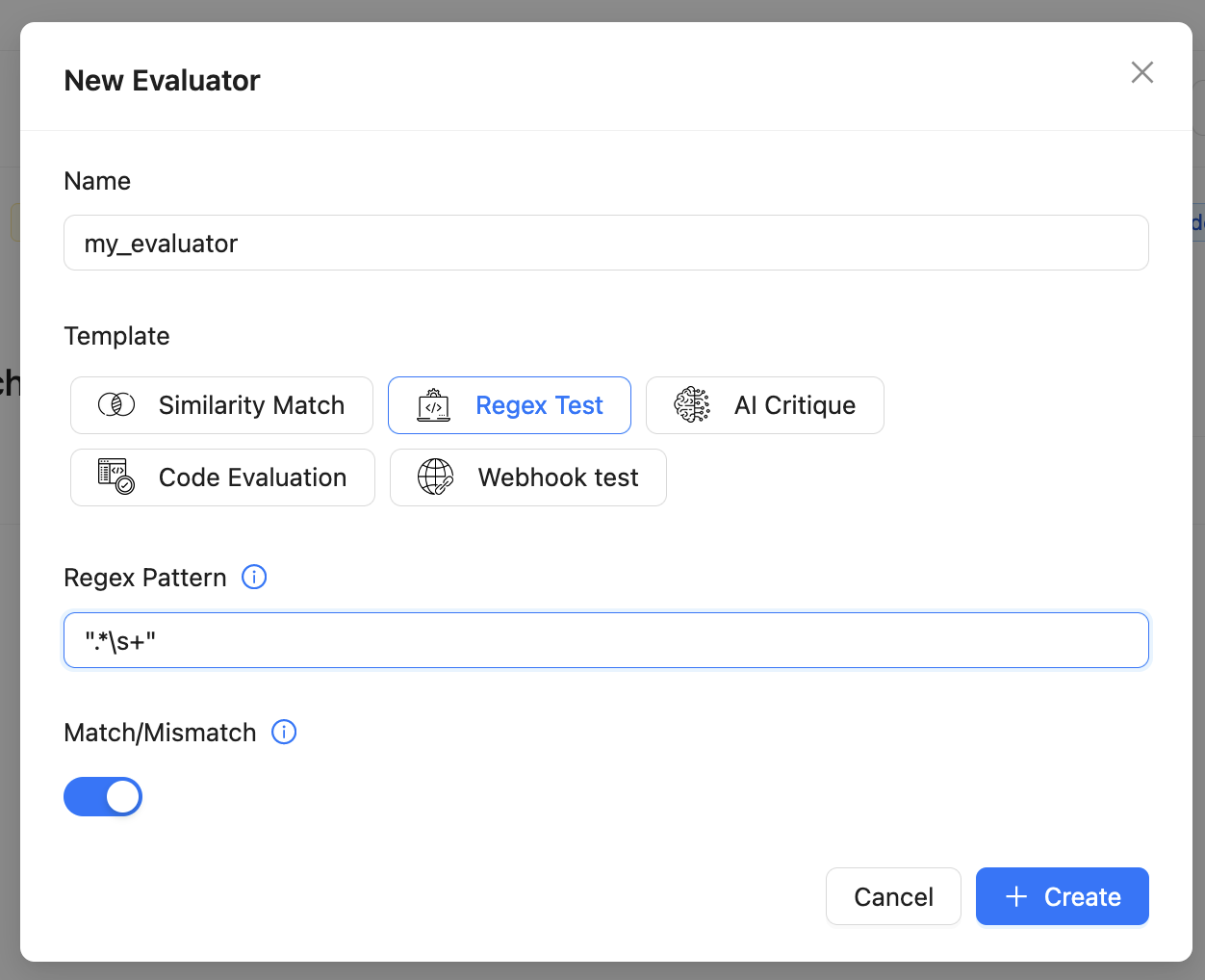
- Reusable Evaluators: Configure evaluators such as similarity match, regex match, or AI critique and use them across multiple evaluations.
Evaluation Reports
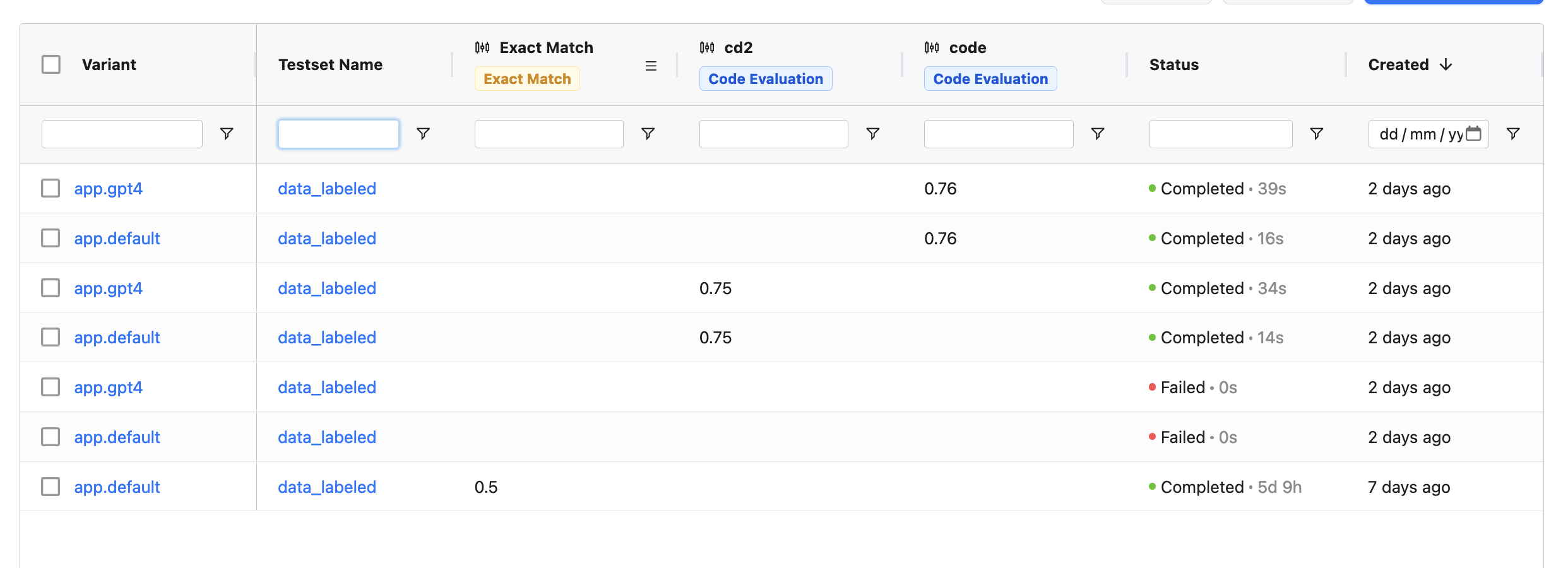
- Dashboard Improvements: We've upgraded our dashboard interface to better display evaluation results. You can now filter and sort results by evaluator, test set, and outcomes.
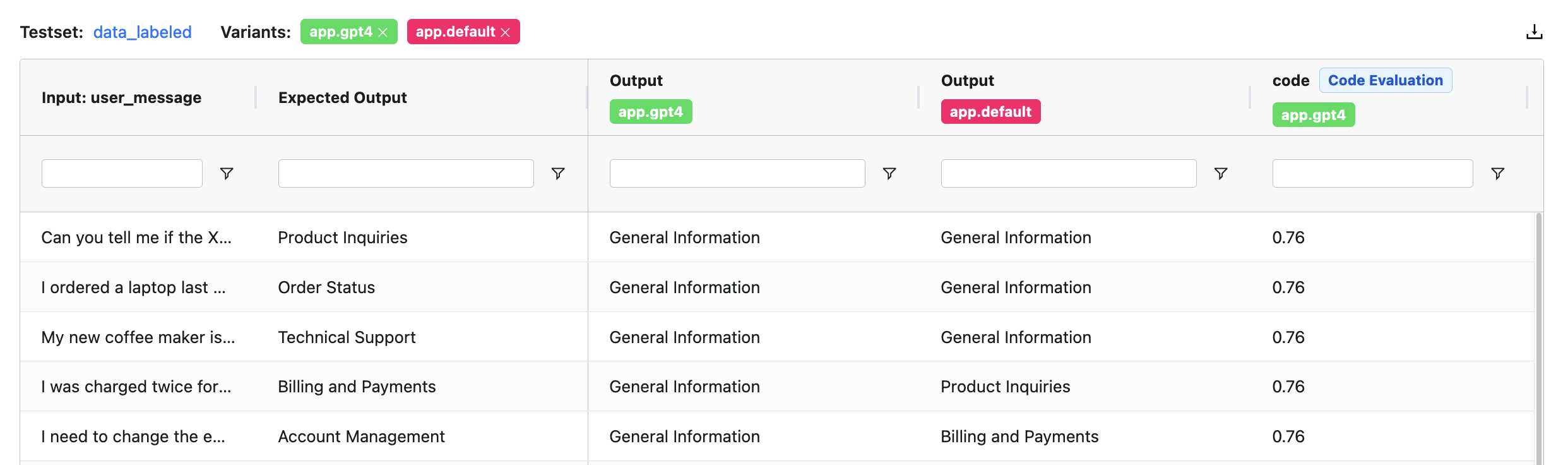
- Comparative Analysis: Select multiple evaluation runs and view the results of various LLM applications side-by-side.
Adding Cost and Token Usage to the Playground
12th January 2024
v0.7.1
This change requires you to pull the latest version of the agenta platform if you're using the self-serve version.
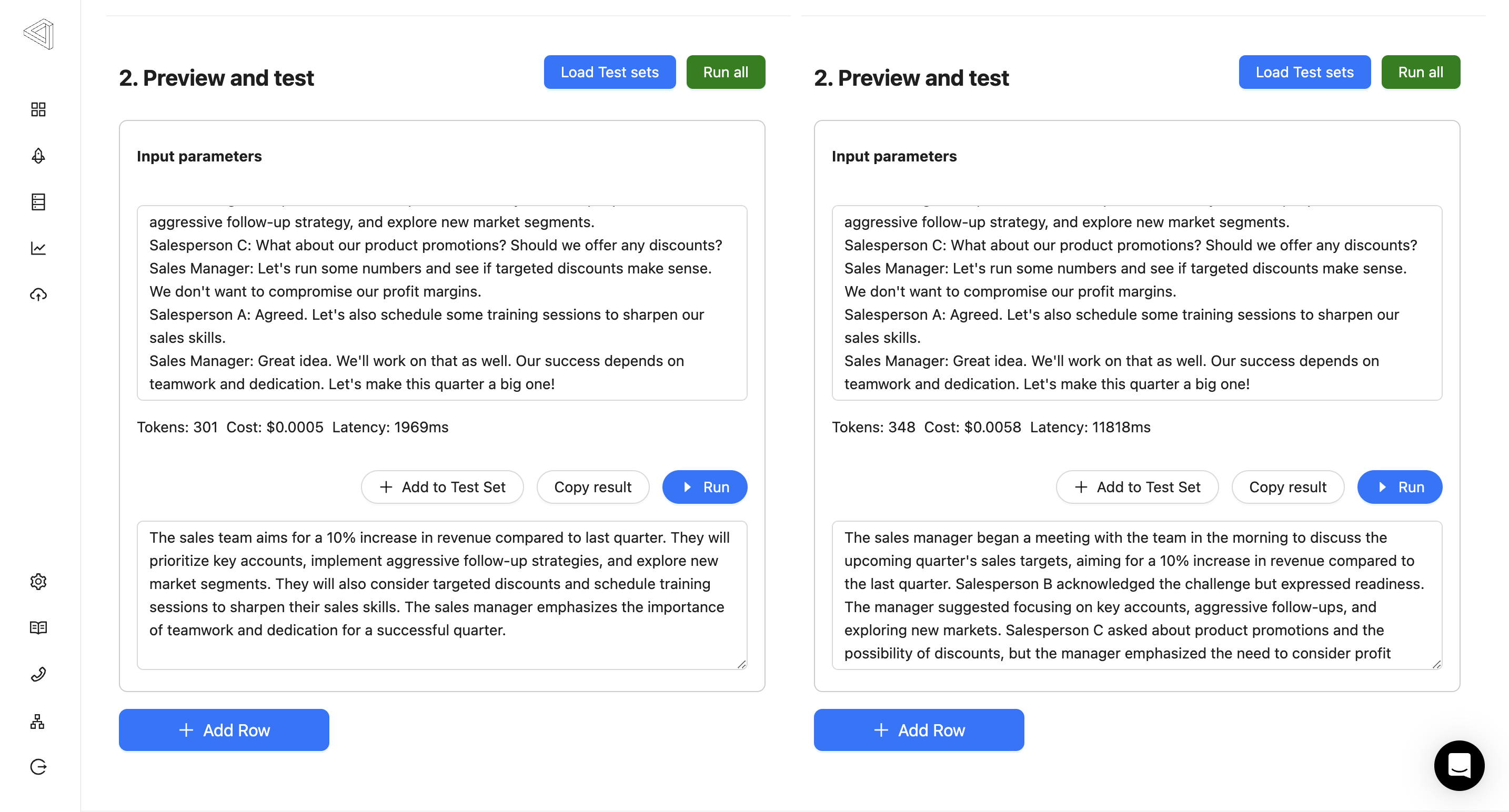
We've added a feature that allows you to compare the time taken by an LLM app, its cost, and track token usage, all in one place.
----#
Changes to the SDK
This necessitated modifications to the SDK. Now, the LLM application API returns a JSON instead of a string. The JSON includes the output message, usage details, and cost:
{
"message": string,
"usage": {
"prompt_tokens": int,
"completion_tokens": int,
"total_tokens": int
},
"cost": float
}
Improving Side-by-side Comparison in the Playground
19th December 2023
v0.6.6
- Enhanced the side-by-side comparison in the playground for better user experience
Resolved Batch Logic Issue in Evaluation
18th December 2023
v0.6.5
- Resolved an issue with batch logic in evaluation (users can now run extensive evaluations)
Comprehensive Updates and Bug Fixes
12th December 2023
v0.6.4
- Incorporated all chat turns to the chat set
- Rectified self-hosting documentation
- Introduced asynchronous support for applications
- Added 'register_default' alias
- Fixed a bug in the side-by-side feature
Integrated File Input and UI Enhancements
12th December 2023
v0.6.3
- Integrated file input feature in the SDK
- Provided an example that includes images
- Upgraded the human evaluation view to present larger inputs
- Fixed issues related to data overwriting in the cloud
- Implemented UI enhancements to the side bar
Minor Adjustments for Better Performance
7th December 2023
v0.6.2
- Made minor adjustments
Bug Fix for Application Saving
7th December 2023
v0.6.1
- Resolved a bug related to saving the application
Introduction of Chat-based Applications
1st December 2023
v0.6.0
- Introduced chat-based applications
- Fixed a bug in 'export csv' feature in auto evaluation
Multiple UI and CSV Reader Fixes
1st December 2023
v0.5.8
- Fixed a bug impacting the csv reader
- Addressed an issue of variant overwriting
- Made tabs draggable for better UI navigation
- Implemented support for multiple LLM keys in the UI
Enhanced Self-hosting and Mistral Model Tutorial
17th November 2023
v0.5.7
- Enhanced and simplified self-hosting feature
- Added a tutorial for the Mistral model
- Resolved a race condition issue in deployment
- Fixed an issue with saving in the playground
Sentry Integration and User Communication Improvements
12th November 2023
v0.5.6
- Enhanced bug tracking with Sentry integration in the cloud
- Integrated Intercom for better user communication in the cloud
- Upgraded to the latest version of OpenAI
- Cleaned up files post serving in CLI
Cypress Tests and UI Improvements
2nd November 2023
v0.5.5
- Conducted extensive Cypress tests for improved application stability
- Added a collapsible sidebar for better navigation
- Improved error handling mechanisms
- Added documentation for the evaluation feature
Launch of SDK Version 2 and Cloud-hosted Version
23rd October 2023
v0.5.0
- Launched SDK version 2
- Launched the cloud-hosted version
- Completed a comprehensive refactoring of the application